Single Cell RNAseq Omixatlas- FAQs
Introduction
Single-cell RNA sequencing has emerged as the technique of choice for researchers trying to understand the cellular heterogeneity of tissue systems under physiological and pathological conditions. Polly provides structured and curated Single-cell RNAseq data in various counts formats as per the need of the research. The data is machine-actionable and analysis-ready for any downstream needs.
Polly can bring in data from a variety of public sources as per the needs as long as the raw counts matrix and metadata are available. Some of the common public sources for Single-cell RNAseq data are:
- Gene Expression Omnibus
- Expression Atlas
- Human cell atlas
- Single Cell Portal
- Tabula sapiens
- Covid-19 Cell Atlas
- Array Express
- Publications
How is a Single Cell RNA-Seq dataset defined on Polly?
A Single-cell RNAseq dataset on Polly represents a curated collection of biologically and statistically comparable samples. A dataset on Polly is a single entity based on its representation in publication or source.
Dataset ID Nomenclature
| Source | Source Format | Polly Format |
|---|---|---|
| GEO | For every study, there is a series ID and a platform ID given on GEO. Platform identifier: A Platform record is composed of a summary description of the array or sequencer. Each Platform record is assigned a unique GEO Identifier(GPLxxx). Series: A Series record links together a group of related samples and provides a focal point and description of the whole study. Each Series record is assigned a unique GEO Identifier(GSExxx). - A Series record can be a SubSeries or SuperSeries. - SuperSeries is all the experiments for a single paper/study and is divided into SubSeries which are different technologies. | Format: GSExxxxx_GPLXXXXX All dataset IDs on Polly are GEO subseries |
| Expression Atlas Human cell atlas Array Express | Studies submitted on these databases/portals have unique IDs associated with them. Eg. E-MTAB-9841, E-HCAD-56, E-GEOD-175929, E-CURD-102 etc. | Datasets for which data is fetched from these sources follow the same nomenclature as that of the source. Eg. E-MTAB-9841, E-HCAD-56 etc |
| Single Cell Portal(SCP) | Studies on SCP have a unique ID associated with them Eg. SCP2331 | Studies fetched from the Single Cell Portal follow the same nomenclature as that of the source. The unique dataset ID format is SCPxxxxx Eg.SCP2331 |
| Tabula sapiens | Studies associated with Tabula Sapiens Consortium - Human cell atlas of nearly 500,000 cells from 24 organs are available as dataset ID - ‘Tabula Sapiens- organ name’ Eg. Tabula Sapiens - Spleen | All 24 datasets on Polly are available with a unique dataset ID format as: 'TS_organ name' where TS stands for ‘Tabula Sapiens’ Eg. TS_Tongue |
| Covid-19 Cell Atlas | Studies related to Covid-19 disease: Healthy Donors or Patient Donors Dataset Identifiers are unique for each dataset/study. The dataset identifiers can be - Tissue and/or author name Eg. Lung parenchyma Vieira Braga et al. - Key tissue/cell type associated with the study Eg. Peripheral Blood Mononuclear Cells (PBMCs) - Other format Eg. COV028A2 | - For datasets where the associated publication is given: A unique dataset ID as the PMID of the paper - In case, a publication reference is unavailable, the dataset ID is the same as that on the source |
| Publication | - | Studies for which data is taken from publication directly (not from the above sources) are available with a unique dataset ID as the PMID of the paper Eg. PMID35664061 |
What are the different options within the Single-cell datasets on Polly
Based on the needs of the research, Polly can provide a Single-cell dataset as any of the following outputs
1. Raw unfiltered counts
This format contains one H5AD file containing raw counts for unfiltered cells and genes as the data matrix, curated sample level metadata, and normalized feature names. More details are in the subsequent sections. This format is useful if the research needs raw counts to be processed in a custom manner.
2. Polly processed counts
This format contains 2 H5AD files.
a. One H5AD file is the same as mentioned in the Raw unfiltered counts section.
b. The second one stores the following
i. processed counts using a consistent pipeline for filtering cells/genes, normalizing the counts, and annotating cell types using the markers from the associated publication.
ii. Raw counts after filtering out the cells and genes as per consistent Polly’s SC pipeline.
iii. Curated sample-level metadata and normalized feature names.
The pipeline provides default standard parameters following best practices at every processing step which can be customized as per requirement.
More details are in the subsequent sections.
Details
1. Raws unfiltered counts
1.1. Starting Point
Single-cell raw count data is typically available in several common file formats across most public resources. For raw counts, data from the source is fetched in the following formats
- Matrix Market (MTX) Format
- Tabular Formats (e.g., CSV, TSV)
- Hierarchical Data Format (e.g. h5ad, suerat, h5)
1.2 Processing details
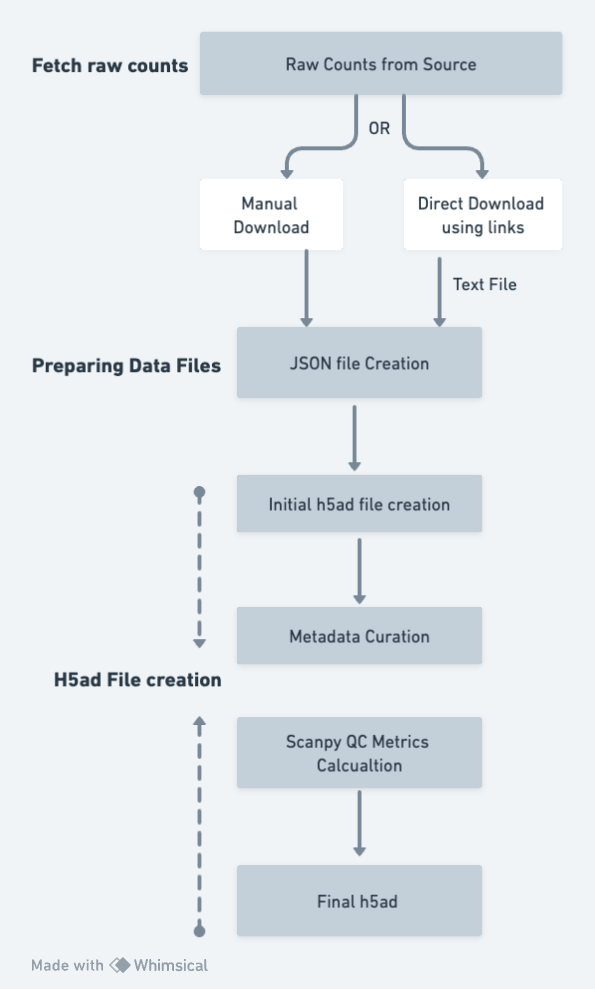
Processing Flow
The pipeline for raw counts includes the following steps:
-
Fetching Raw Counts: The starting point for the pipeline is getting the raw counts from the source by
- Either downloading data directly from the source - A text file is created with links for downloading
- Downloading manually
-
Preparing Data files: A JSON file is created for the pipeline to run.
- A JSON file with all the required input parameters is created. As per the parameters given in the JSON file, further steps in the pipeline are run
- In case raw counts are downloaded from the source directly, the file is unzipped and data is arranged in a structured way
-
Creating h5ad: With the input as the above JSON file, the pipeline starts to create the initial h5ad.
- Programmatic checks are performed to ensure the data matrix contains raw counts only
- If the matrix is not found to be in the correct format (as per the raw count acceptable values), the pipeline stops
- Pipeline accepts the raw counts as per defined the acceptable values, i.e. integer values and >1000
- The index for cell data is sample: barcode and information with respect to each sample: barcode (cell id = sample: barcode) is added
- Feature IDs are converted to Hugo Symbols (or Ensembl IDs where conversion to Hugo symbols is not available or ambiguous)
- Initial h5ad is created
-
Metadata Curation:
- The curation pipeline adds curated metadata to the file - sample/cell level metadata is added to the h5ad file
- The curation pipeline generates dataset metadata
-
QC metrics: Scanpy QC metrics are calculated and added to the h5ad file
-
Final h5ad: The final h5ad file is saved, consisting of QC metrics, curated metadata, raw counts matrix
1.3 Curation and Metadata details
On Polly, every dataset and its corresponding samples are tagged with some metadata labels that provide information on the experimental conditions, associated publication, study description and summary, and other basic metadata fields used for the identification of dataset/samples.
There are three broad categories of metadata available on Polly such as:
a) Source Metadata: Metadata fields that are directly available from the Source and provided in a Polly-compatible format.
b) Polly - Curated: These are curated using Polly’s proprietary NLP-based Polly-BERT models and reviewed by expert bio-curators to ensure high-quality metadata. Some of the Polly curated metadata fields are harmonized using specific biomedical ontologies and the remaining follow a controlled vocabulary.
c) Standard identifiers - Identifier metadata tag for datasets, giving information on the basic attributes of that dataset/study.
Metadata for every dataset is available at 3 levels:
I) Dataset-level metadata - General information about the overall experiment/study, for eg, organism, experiment type, and disease under study.
II) Sample-level metadata - Information about each sample related to Eg. Drug, tissue.
III) Feature-level metadata: Information on the genes/features that are consistent across samples.
Details on each metadata field present at the dataset, sample, and feature level are given here
1.4 Output H5AD format and details
H5AD file for raw counts data offering will be available to the user with the following information:
-
Raw counts
<adata.X>slot: The raw expression matrix is available in this slot, providing information on the genes and cells as provided by the author. The raw counts will available be as:- Integer counts (with an exception of some datasets from Expression Atlas which may contain fractional values)
- Values >1000
- Values not less than 0
- Sparse matrix
-
Complete Sample Metadata in
<adata.obs>slot: All the cell/sample level metadata information is available in this slot as per the metadata table given above- Polly-Curated Metadata
- Scanpy QC metrics - QC metrics include n_genes_by_counts, total_counts, total_counts_mt, and pct_counts_mt.
- Source Metadata
- Standard Identifier Metadata
-
Processing Details
<adata.uns>slot: Unstructured metadata on the processing-related details is available in this slot such as:- Tools/packages along with their versions used to convert the matrix from source to H5AD file
- curation model version (for eg. PollyBert_v1)
- ontology version
- raw file formats
- scanpy, anndata version
-
<adata.uns>slot: QC Metrics such as mt, n_cells_by_counts, mean_counts, pct_dropout_by_counts & total_counts
1.5 Report
A detailed data report is available for each dataset which can be viewed /downloaded using the given link. The following information corresponding to the dataset will be available in each report:
A) General Information: Dataset Summary
- Organism
- Number of cells
- Number of samples
- Disease
- Dataset Source
- Data split: Yes/No
- In the case of ‘Yes’, the name of the factor used for splitting is given. Eg. Tissue, disease, etc.
- Size of the data matrix
- Annotated cell types from Source

Sample information for dataset summary
B ) Experiment design
- SC chemistry
- Design
C) Pre-processing
- Reference genome to which the sequenced reads were mapped
- Reference genome annotation used for transcript quantification
- Software pipeline and version used for read mapping and expression quantification
D) Sample/cell Level Metadata Attributes
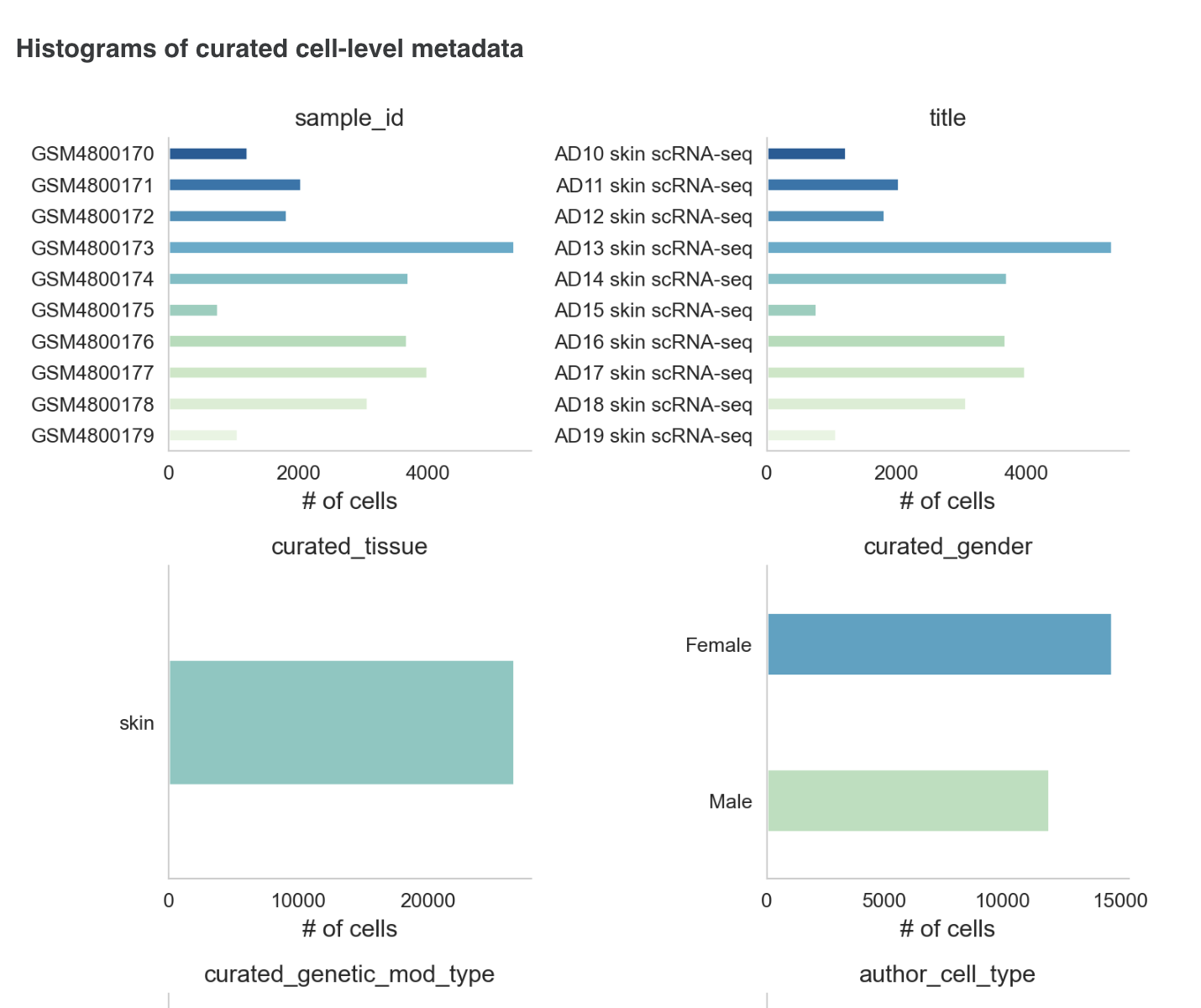
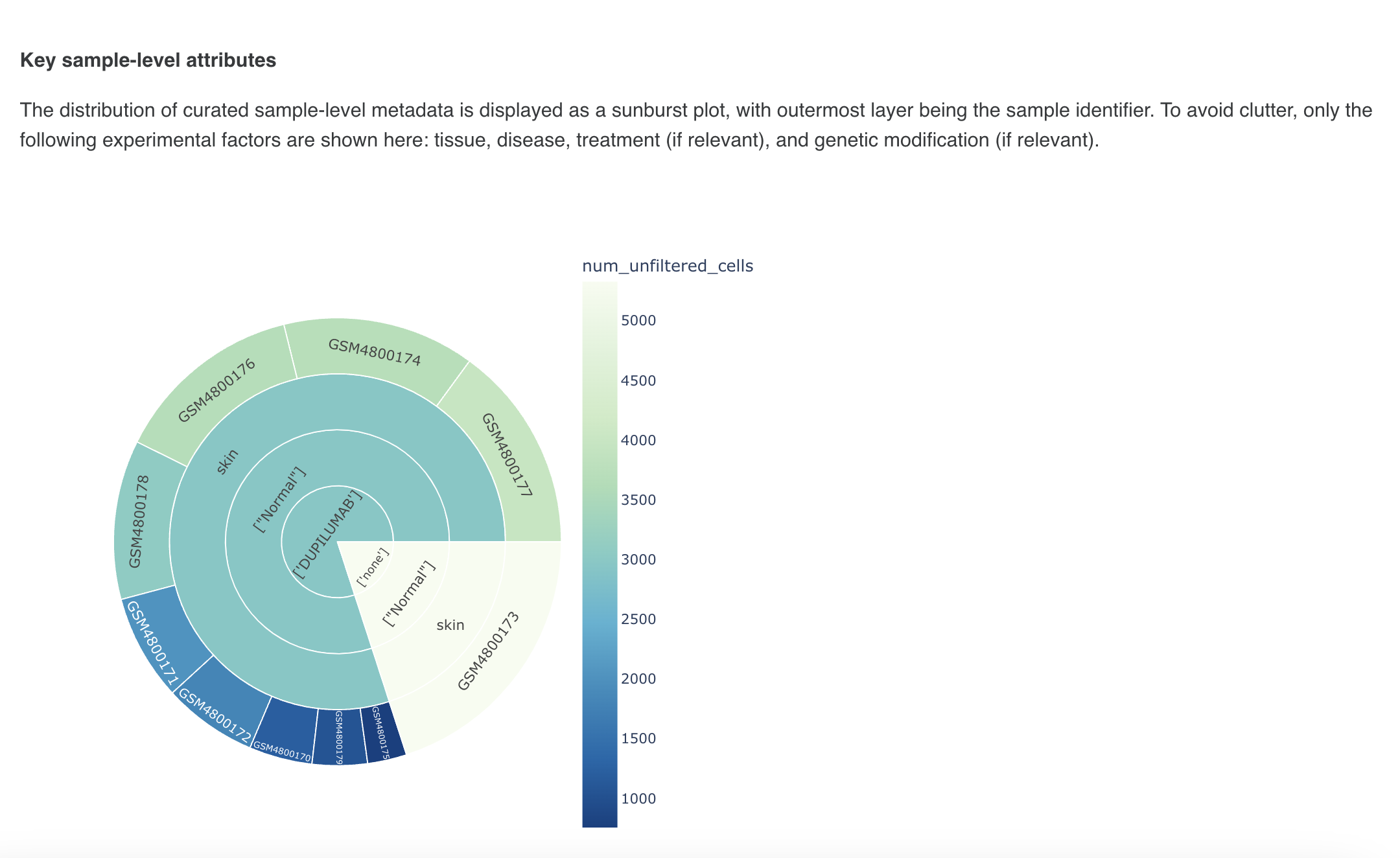
E) Basic Data QC
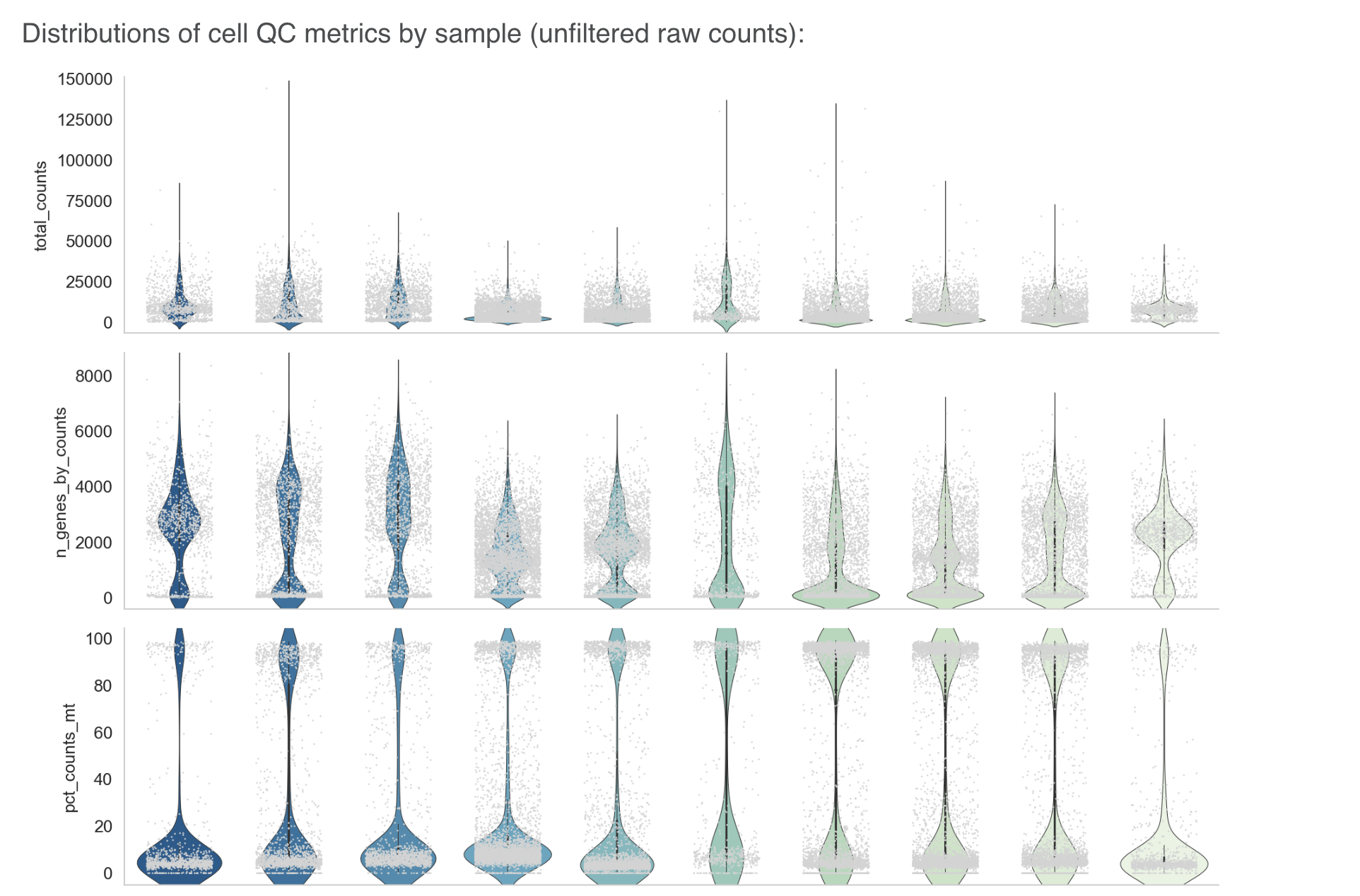
F ) Data QA Analysis: This section provides a table showing the data-related checks performed internally along with the final output
- Metadata QA - Quality checks performed for metadata at the dataset and sample/ cell-level metadata
- Data matrix QA
2. Polly Processed Data
2.1. Starting point
For processing SC datasets using Polly’s standardized pipeline, the starting point is the h5ad file containing raw unfiltered counts created for the raw counts data. The inputs for the processing pipeline are:
The H5ad file should contain required sample/cell and feature level metadata. Features should be HUGO gene symbols as feature IDs, obs columns must specify batch/sample that will be used for batch correction.
2.2. Processing details
The pipeline includes the following steps:
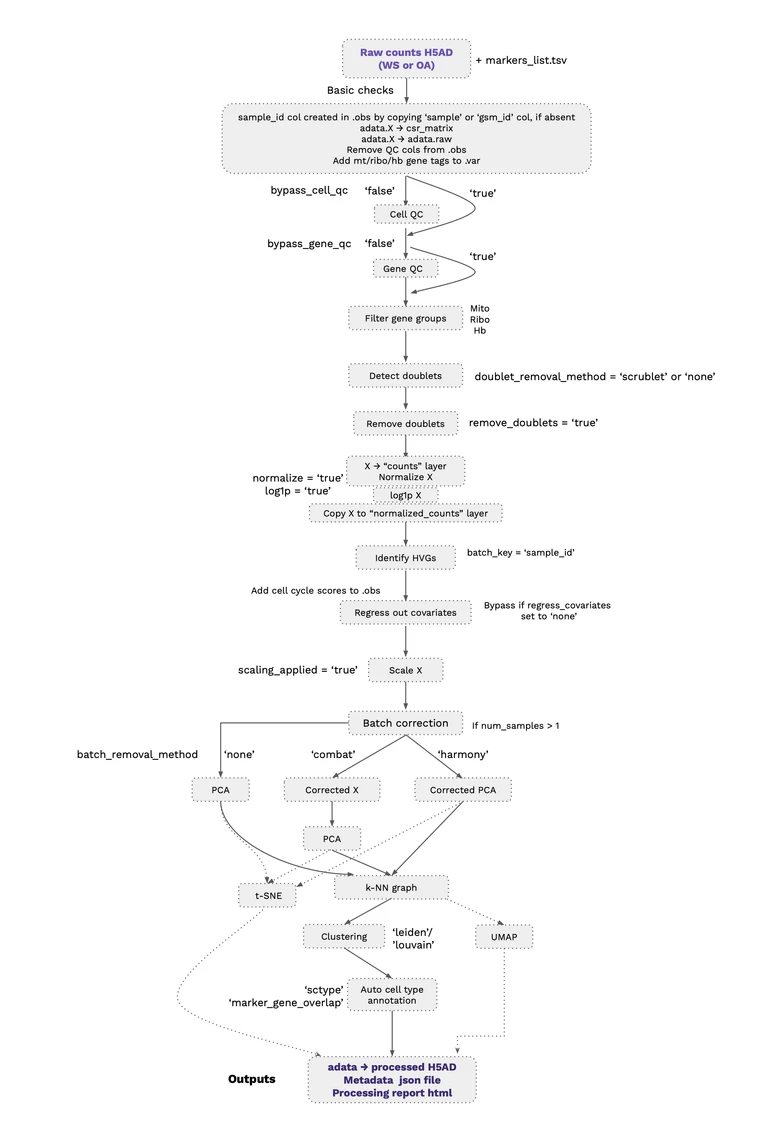
1. Preparing files
- A JSON file is created with all the required input parameters and method choices for the processing workflow
- Marker list provided with positive and negative markers for the cell types of interest
2.Processing Workflow: Standard pipeline workflow consists of the following stepsguided by best practices recommendations:
a. Data Checks
Data checks are done such as
- X contains raw counts
- X is a sparse matrix in csc_format
- mt,ribo, and hemo tags are added to genes
- Copy of unfiltered counts matrix from X to raw slot
b. Quality Control
With the gene expression matrix ready (raw counts matrix), the next step is to filter out low-quality cells and genes before further processing. Filtering of cells is done on a per-sample basis, using adaptive cutoffs per dataset
- Cell filtering
Following the best practices guide, we use ratios instead of hard thresholds. This adapts cutoffs according to the distribution in each dataset. Outlier cells crossing at least one of the following thresholds are removed (MAD is median absolute deviation)
log1p_total_counts > or < 5 MAD,log1p_n_genes_by_counts > or < 5 MAD,pct_counts_in_top_20_genes > or < 5 MAD,pct_counts_Mt > 3 MAD or > 8%- Gene filtering: genes expressed (counts > 0) in less than 3 cells are removed
c. QC metrics calculation
QC metrics are calculated for ribo & hemo genes as well, but genes are not removed based on these metrics.
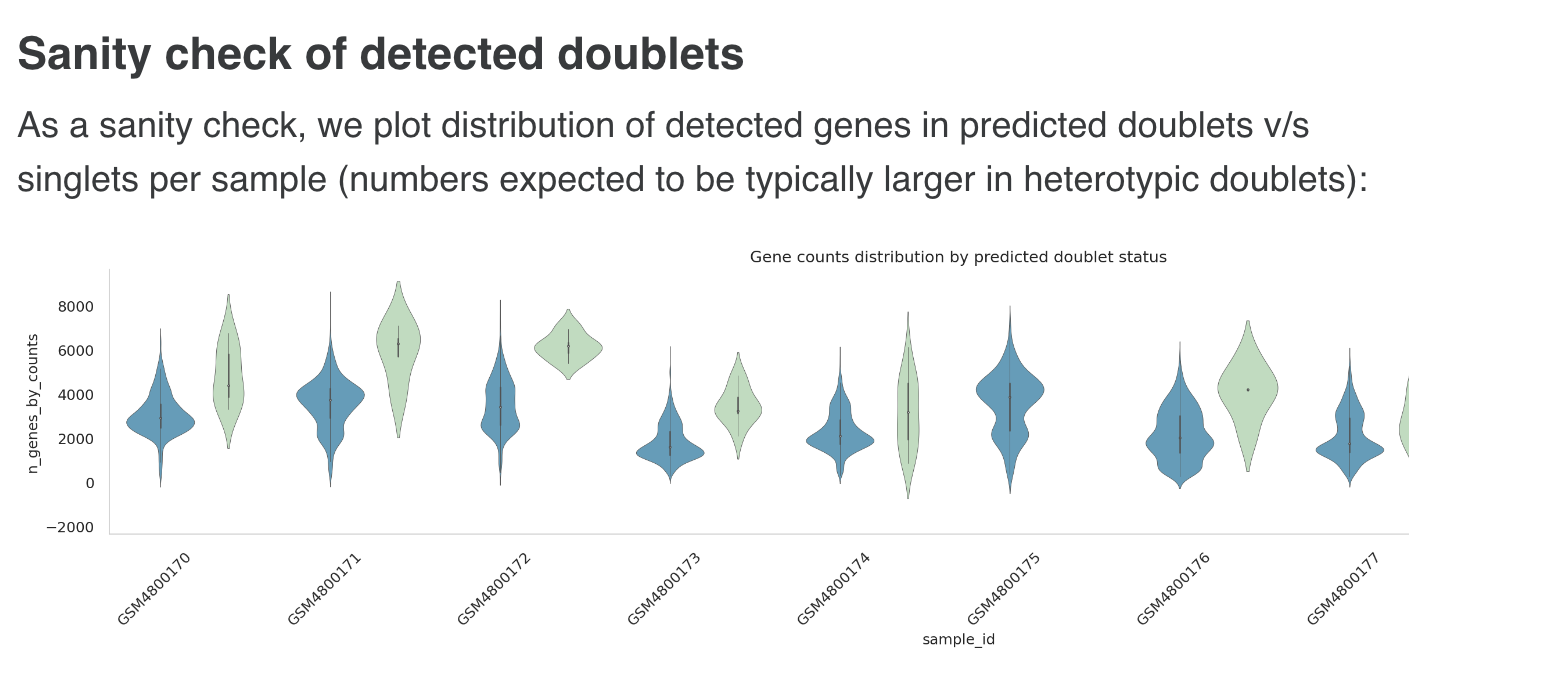
d. Doublet detection
Detection of probable doublets and filtering out predicted doublets from the counts matrix. This is done using the Scrublet tool, which has a Python implementation. [Scrublet is also being used in the EBI SC Expression Atlas pipeline and has been known to perform better against other methods, particularly in terms of speed and scalability (e.g. this review and study)]
Default parameters for Scrublet:
- Doublet rate: 0.06
- Min counts: 2
- Min cells : 3
- Min gene variability %: 85
- Principal components: 30
e. QC metric re-computation
Following filtering and doublet removal, the QC metrics are re-computed (using scanpy.pp.calculate_qc_metrics function) on the updated filtered matrix and stored in obs/var:
-
obs:
'total_counts', 'n_genes_by_counts','pct_counts_in_top_20_genes','pct_counts_mt','pct_counts_ribo','pct_counts_hb' -
var:
'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts
f. Normalization
Normalization is performed to reduce the technical component of variance in the data, arising from differences in sequencing depth across cells. It is performed based on the following choices:
- Method: library size/total counts normalization (implemented by
scanpy.pp.normalizefunction) - target_sum:
None(this is the default option in scanpy and amounts to setting the library size to the median across all cells; best practices guide discusses the use of alternate fixed thresholds like 104 or 106 can introduce over-dispersion) - log1p:
True - Scaling:
True, with zero_center=False(this will be performed after the HVG step)
Note: Before normalization, the filtered counts matrix is saved to a separate “counts” layer (adata.layers["counts"]), and X is updated with the normalized counts matrix. A copy of the normalized (and optionally log1p) counts matrix will also be saved in a separate “normalized_counts” layer, this will preserve the normalized data prior to scaling and batch correction steps
g. HVG identification
Feature selection is needed to reduce the effective dimensionality of the dataset, and retain the most informative genes for downstream steps like PCA and neighbor graph
-
Highly Variable Genes (HVG) are identified using the
scanpy.pp.highly_variable_genesfunction with the following settings: -
HVG method:
"Seurat"(default, uses the log-normalized counts matrix in X) - n_top_genes (# HVGs identified):
2000 - batch_key setting:
"sample"(this corresponds to batch-aware feature selection providing a lightweight form of batch correction to reduce technical differences between samples, see e.g. best practices guide) - subset:
False- the expression matrix is not subsetted to the HVGs. All genes are retained and a highly_variable column gets added to the .var slot
h. Batch Effect Correction
Batch effect is checked in the data using “sample_id” as the batch variable
- In a manual workflow, batch effects in the dataset will be checked visually on a UMAP or tSNE as well as the quantitative metrics of batch effects in the data. In the pipeline, batch effects in the data are checked by calculating established quantitative metrics of batch mixing. The following quant metrics to be adopted (these are provided through scib and scib-metrics libraries, which were released along with a recent benchmarking study of single-cell data integration methods):
- Adjusted rand index comparing batch labels and leiden clusters (ARI)
- Normalized mutual information between batch labels and leiden clusters (NMI)
- Principal component regression variance using batch variable (pcr_batch)
- Scaled graph integration local inverse Simpson’s index (Graph iLISI)
- Acceptance rate from batch k-BET test (kbet_accept_rate)
For ARI-PCR batch above, values closer to 0 indicate good batch mixing; for iv-v, values closer to 1 indicate the absence of significant batch effects in the data
- For the standard pipeline, batch integration is performed in the PCA space using Harmony method with default settings (via the Scanpy wrapper
sc.external.pp.harmony_integrate). The batch-corrected PCA representation is stored in the .obsm slot as"X_harmony"key. This corrected PCA matrix is used for the subsequent kNN neighbor graph, t-SNE and clustering steps. The underlying expression matrices in X and "normalized_counts" layer remain uncorrected, and retain their sparse format, which avoids a large increase in the effective dataset size. - Following the batch correction step, the quantitative metrics of batch mixing are re-calculated on the adjusted PCA matrix. The pre and post batch correction metrics are saved to the .uns slot (“batch_correction_metrics”) enabling a quantitative assessment of the impact of the batch integration in mitigating batch variation in the data distribution.
- Batch correction details are provided in the .uns slot as a dictionary:
adata.uns["batch_correction_details"] = {"batch_correction_applied": True, "method": 'harmony', batch_variable: "sample_id"}
i. Dimensionality reduction
This step is necessary to reduce the dimensionality of the data prior to clustering, and to enable visualization for exploratory analysis. Following data embeddings are provided by running the relevant scanpy functions:
- PCA (n_pcs = 50 top PCs ranked by explained variance):
'X_pca'in obsm,'PCs'in varm slot - Nearest-neighbor graph in PC space: n_neighbors=50, dimensionality of PC space = 40 or number of top PCs explaining 90% variance, whichever is smaller;
'distances'and'connectivities'in obsp slot - Uniform Manifold Approximation and Projection (UMAP):
'X_umap'in obsm slot - t-Distributed Stochastic Neighbor Embedding (t-SNE):
'X_tsne'in obsm slot
j. Cell clustering: Clustering is performed on the processed and dimensionally reduced data matrix to identify (probable) similar groups of cells, possibly representing distinct cell types/states.
- Leiden graph-based clustering is performed with a fixed resolution (resolution = 0.8)
- The nearest-neighbor graph is constructed in the previous dimensionality reduction step.
- Cluster labels are added to the obs slot in a ”clusters” column
k. Cell type annotation of clusters: This is done based on the marker genes and cell types from the associated publication, using an automated cell type assignment method -ScType
- ScType implementation - Input
- A tab-separated file is created with
- raw/author cell types and corresponding lists of marker genes (one cell type per line, no headers)
- Specification on whether each marker gene is supposed to be present (over-expressed) or absent (under-expressed) in the corresponding cell type.
-
The processed expression matrix in X slot (only the slice of the data corresponding to the supplied marker genes is used for scoring cell types).
-
ScType implementation - Output
-
ScType returns an enrichment score matrix of size
num cell types x num clusters, based on which each cluster gets assigned the raw cell type with the highest score. -
Note: As the expression matrix input to ScType is not batch-corrected, batch differences are accounted for by standardizing (z-scoring) the expression values gene-wise within each individual batch, then concatenating the batches (instead of z-scoring the expression values at the dataset level) before the enrichment score matrix calculation. This ‘batch-aware’ annotation handles corner cases where batch effects in the dataset impacts the marker genes and the cell type annotation in turn
-
Annotated Tags:
-
Following sample-level metadata columns get added to obs (these would be uniform across all cells in each cluster):
i. polly_curated_cell_type: Raw cell type associated with the cell
ii. polly_curated_cell_ontology: Cell type associated with the cell, curated with standard ontology
iii. marker_gene_present: Raw cell type and corresponding present (over-expressed) marker genes corresponding to the assigned cell type against each cell
iv. marker_gene_absent: Raw cell type and corresponding absent (under-expressed) marker genes corresponding to the assigned cell type against each cell
-
Following outputs of the cell annotation step are saved to the uns slot of the anndata object:
i. A table of raw/author cell type predictions by cluster, providing the corresponding ScType scores and confidence values, along with the subset of marker genes for the assigned cell type which are differentially expressed in the annotated cluster (using the cutoffs log2fc > 0 and adjusted t-test p-value < 0.05).
ii. Marker genes dictionary used for the cell type annotation step ({cell_type:[markers]})
iii. Additionally, differentially expressed genes from one-vs-all comparison per cluster are calculated by calling the sc.tl.rank_genes_groups function separately on each individual batch, then aggregating the DGE results across all batches per cluster. This handles batch effects in the normalized data matrix and ensures robust cluster-level markers are selected. DE genes are aggregated and ranked by # of batches in which the gene is DE, the combined p-value (Fisher’s method), and the mean t-test score, in that order. The DGE results are automatically saved to the .uns slot as a single dataframe
("rank_genes_groups").
l. Saving the data
The parameter dictionary will be saved to the uns slot, after adding a time stamp as the “time_stamp” key to the params dict. The X matrix will be converted to csc_matrix format and the processed anndata object will be saved in H5AD format and pushed to Polly’s omixatlas. Further, details of the processing performed (parameters/method choices, QC metrics, and associated plots) are bundled as a separate comprehensive HTML report and provided with the data file.
Split Datasets
Datasets are split based on the following categories:
- Disease (Normal will not be separated as another dataset, only diseases will be split)
- Organism
- Tissue
- Assay
For split datasets, the nomenclature of dataset ID is as follows:
Polly dataset ID_Split factor, wherein the Polly dataset ID is the format mentioned above for different sources and split factor is the name of the disease, organism, tissue, or Assay.
Eg. GSE156793_GPL24676_Kidney, GSE156793_GPL24676_Liver
2.3. Curation and Metadata details
Metadata curation for Polly annotated data is the same as raw counts data (given above). However, there are some additional fields that are present for every polly-processed dataset in addition to the existing fields available for raw unfiltered data.
Details on each metadata field present at the dataset, sample, and feature level are given here
2.4. Cell Annotation Method
We have implemented an author-assisted approach for cell type annotation of clusters using an automated cell type assignment method, ScType. The inputs for ScType are the marker genes and cell types curated from the associated publication
Input to ScType implementation:
- The marker list is given as a tab-separated file with raw/author cell names and corresponding comma-separated stringified lists of marker genes (one cell type per line, no headers).
- Specification on whether the marker gene is present (over-expressed) or absent (under-expressed) in the corresponding cell type is also given in the file.
- To specify this information along with the marker lists, each cell name in the list is appended with a suffix tag ‘+’ or ‘-’ to indicate whether present or absent marker genes are indicated on that line. If a cell type is associated with both types of markers, these are to be grouped by type and provided in separate lines.
Example of a TSV file format:
In the above example, raw cell type C1 has 2 present marker genes (g1, g2) and 2 absent marker genes (g3, g4) mentioned in the publication. Cell type C2 only has a single present marker gene (g5).Note: The suffix tag is optional. If it is not provided, by default the genes are assumed to represent over-expressed markers only.
- Processed expression matrix in X slot (only the slice of the data corresponding to the supplied marker genes is used for scoring cell types).
Outputs of cell type annotation step:
ScType returns an enrichment score matrix of size num cell types x num clusters, based on which each cluster gets assigned the raw cell type with the highest score. If the ScType score was <0 for any cluster, that cluster is left unlabeled ('Unidentified' tag).
Annotated information:
- Following sample-level metadata columns are added to the obs slot (these would be uniform across all cells in each cluster):
- polly_raw_cell_type: Raw cell type associated with the cell
- polly_curated_cell_type: Cell type associated with the cell, curated with standard ontology
- curated_cell_ontology_id: The normalized Cell Ontology ID corresponding to the assigned cell type
- marker_gene_present: Raw cell type and corresponding present (over-expressed) marker genes corresponding to the assigned cell type against each cell
- marker_gene_absent: Raw cell type and corresponding absent (under-expressed) marker genes corresponding to the assigned cell type against each cell
polly_curated_cell_type and urated_cell_ontology_id above are the results of running the raw cell types (curated_cell_type) through the Polly curation library normalizer.
- Following outputs of the cell annotation step are saved to the uns slot of the anndata object:
- A table of raw/author cell type predictions by cluster, providing the corresponding ScType scores and confidence values, along with the subset of marker genes for the assigned cell type which are differentially expressed in the annotated cluster.
- Marker genes dictionary used for the cell type annotation step
In addition to the above outputs, the differentially expressed genes from one-vs-all comparison per cluster, also get automatically saved to the .uns slot (as 'rank_genes_groups')
2.5. Customization
The tools and parameters for processing datasets as per Polly’s processing pipeline are standard. Any changes will be considered a custom request. There are some guardrails such as:
- Markers for the main cell types, mostly from the main figure, subcluster is a custom request
- If markers are not available in publications, then we use databases like CellMarkerDB or PanglaoDB ( 30% of datasets might not have markers clearly mentioned)
Input file can be raw counts, QC filtered or normalized counts
- Splitting datasets ( dataset split as per our criteria of :Disease, Organism, Tissue, Assay or as per split defined in publication )
- QC filter (choice between fixed cutoffs or best-practices adaptive cutoffs per sample or across all datasets)
- Cell filtering level (per sample or whole dataset)
- Gene filter cutoff (# of cells expressed)
- Filtering of gene groups (mitochondrial (mito)/ribosomal (ribo)/hemoglobin (hb))
- Doublet detection (yes/no)
- Normalization: Size factor (value), log1p (true/false), scaling (true/false)
- HVG selection: No. of highly variable genes (value), batch aware HGV selection, dispersion method
- Scaling (true/false) and zero centering (true/false)
- Regressing cell covariates ( none, covariates )
- Batch correction method (combat, harmony)
- Embeddings: # of PCs, # of neighbors for neighborhood graph and clustering
- Clustering: Resolution parameter, Method (Louvian/Leiden)
- Cell Annotation: automated by ScType, marker overlap with differential expressed genes, canonical markers (CellMarkerDB and PangloDB)
- DEGs (by cluster): log fold-change and p-value cutoffs
2.6. Output H5AD format and details
Two H5AD files will be made available to the user.
- Raw unfiltered counts data (Details given above)
- Polly annotated data:
_polly_annotated.h5ad
The following information will be available in the H5AD file (Dataset_id>_polly_annotated.h5ad)
-
Raw filtered counts in
<adata.raw>slot: The expression matrix after filtering out the genes and cells as per Polly's standard processing pipeline is available in this slot- Integer counts
- Sparse matrix
-
Processed filtered counts in
<adata.x>slot: The expression matrix after filtering out the genes and cells and normalising the counts as per Polly's standard processing is available in this slot as:- Float values
- Values < 100
- Sparse matrices
-
Complete Sample Metadata
<adata.obs>slot: All the sample/cell level metadata as per the metadata table given above is available in this slot. This includes- Polly-Curated Metadata
- QC metrics
- Source Metadata
- Standard Identifier metadata
-
Embedding data in
<adata.obsm>slot. This includes the following:- PCA: Principal components minimum
- tSNE: Coordinates of the tSNE plot
- NN: Nearest Neighbour graph
- UMAP: Coordinates of the UMAP plot
-
Unstructured metadata in Uns
slot: This includes the following: - Tools/packages along with their versions used to convert the matrix from source to raw counts H5AD file
- Tools/packages along with their versions used to convert the raw counts H5AD file to Polly processed counts H5AD file
- processing pipeline version (for eg. polly_scRNASeq_pipeline_v1)
- curation model version (for eg. PollyBert_v1)
- ontology version
- scanpy, anndata version
- Parameters used for processing the data (as a dictionary)
- Table of sample-wise QC stats (no. of cells pre/post filtering, along with filtering thresholds applied)
- Table of no. of predicted doublets against the total number of cells pre-filtering, per sample
- A dictionary of markers is available in the publication and employed for cell type curation
- Table of cluster-level cell type predictions from the automated method, along with scores and differentially expressed marker genes for each predicted cell type appearing in the corresponding cluster
- Batch-correction method that is applied, along with tables of batch mixing and bio conservation metrics computed on uncorrected/corrected expression matrices
2.6. Report
A detailed data report is available for each dataset which can be viewed /downloaded using the given link. The following information corresponding to the dataset will be available in each report:
A) Processing Workflow Summary:
Brief information about the steps involved in the processing pipeline
- Quality Control (QC) Checks: The initial step involves rigorous quality control checks to identify and filter out poor-quality cells and genes. This ensures that only reliable data is used for downstream analyses, leading to more accurate biological interpretations.
- Doublet Detection: Doublets, which can arise during sample preparation and confound analysis, were identified and removed using [Doublet Detection Method]. This step ensured the accuracy of subsequent analyses.
- Normalization: Normalization was applied to the processed data to eliminate technical variations and enable meaningful comparisons between cells. [Normalization Method] was used to achieve comparable expression levels across cells.
- Identification of Highly Variable Genes (HVG): Not all genes are equally informative in single-cell RNA-Seq data. We identify highly variable genes that drive biological variation and use them for downstream analyses, improving the robustness of our results.
- Batch Correction: Whenever necessary, batch correction was applied to address potential batch effects present in the dataset. [Batch Correction Method] was used to mitigate batch-related variability, ensuring the biological signal remains intact.
- Cell Type Annotation: Cell types were assigned to individual cells using [Cell Type Annotation Method]. By leveraging known marker genes and reference datasets, cells were labeled with their respective biological identities.
B) General Information:
Dataset Summary
- Organism
- Number of cells
- Number of samples
- Disease
- Dataset Source
- Data split: Yes/No
- In the case of ‘Yes’, the name of the factor used for splitting is given. Eg. Tissue, disease, etc.
- Original size of the raw data matrix
- Data matrix after processing
C) Processing Details
- Quality Control
QC parameters: 1. Minimum total counts per cell: Automatically determined based on dataset 2. Maximum total counts per cell: Automatically determined based on the dataset 3. Minimum number of genes per cell: Automatically determined based on dataset 4. Maximum number of genes per cell: Automatically determined based on dataset
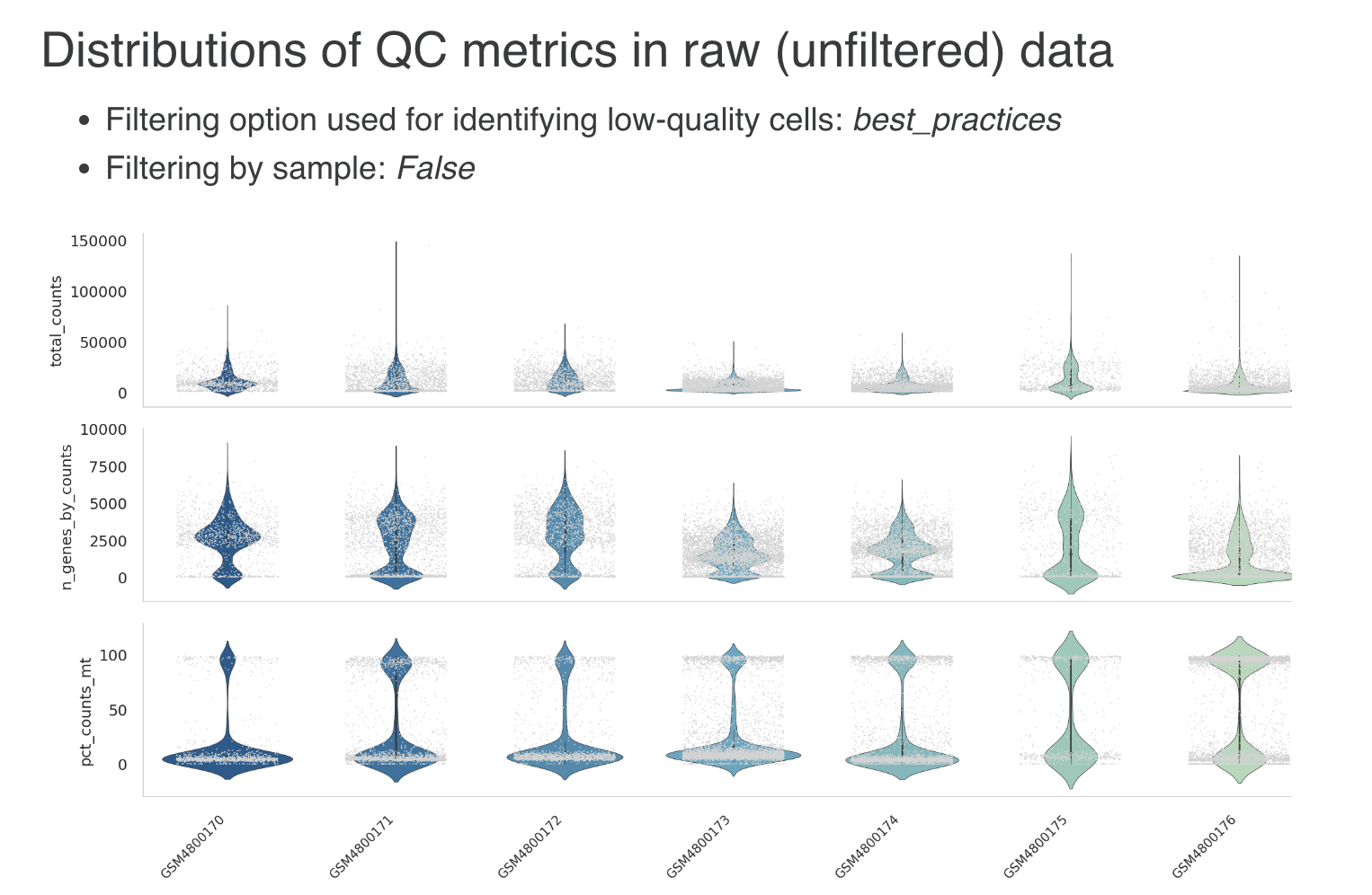
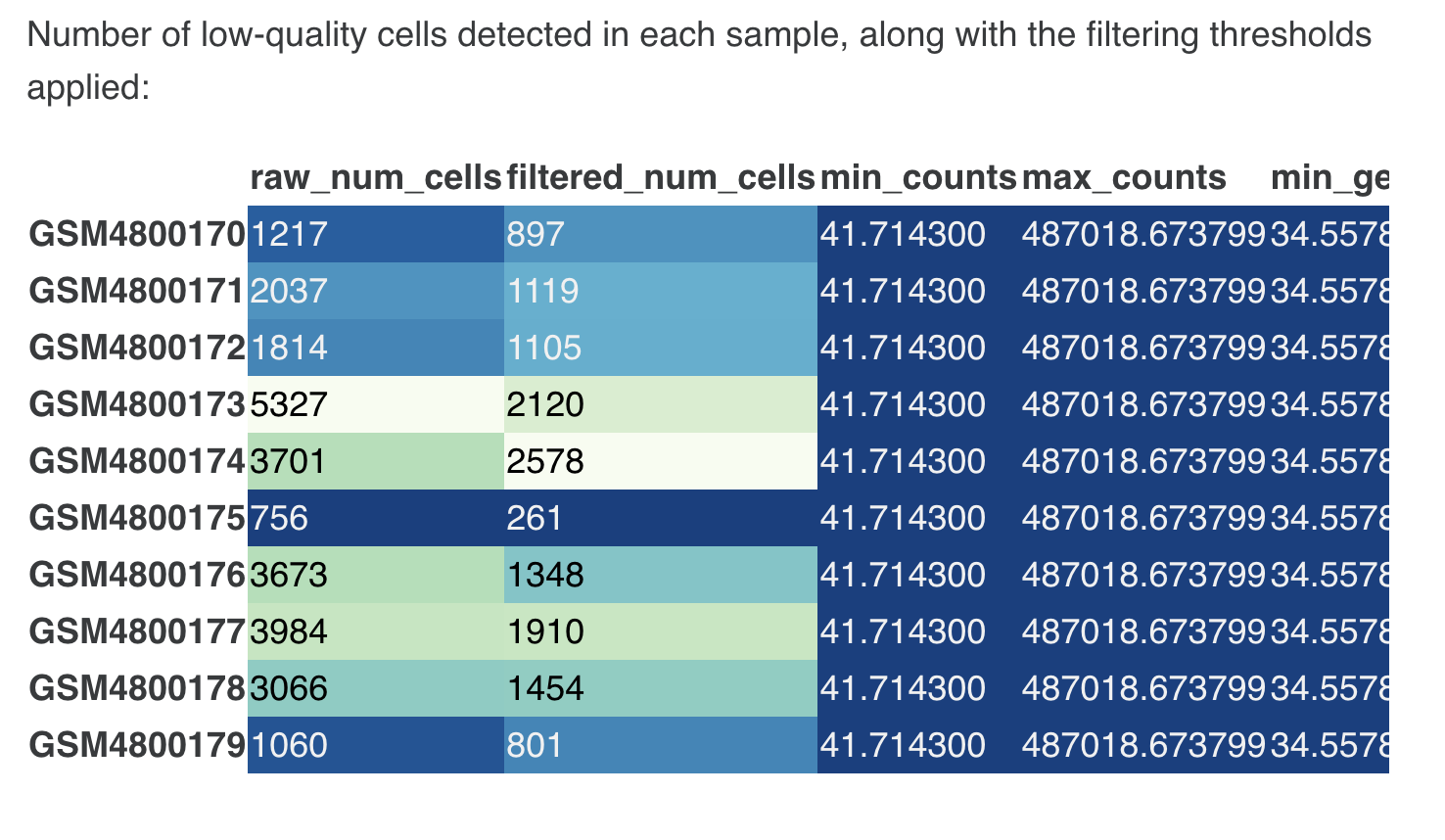
- Filtering low-expression genes :
- Genes expressed in less than 3.0 cells were removed.
- Doublet detection and removal:
- Doublet detection performed with scrublet.
- Parameter settings:
expected_doublet_rate : 0.06min_cells : 3.0min_counts : 2min_gene_variability_pctl : 85.0n_prin_comps : 30
-
Normalization Parameters
-
Highly variable genes parameters
- HVG flavor
- HVG selection method
- batch_key
- Number of top variable features selected
-
Batch Correction
Details on the quantitative metrics computed on the nearest neighbor graph in PC space.
- Batch mixing
- Normalized mutual information between batch and cluster labels (NMI)
- Adjusted rand index comparing batch and cluster labels (ARI)
- Principal component regression variance contribution of batch (PCR_var)
- Graph integration local inverse Simpson’s index (Graph_iLISI)
- Acceptance rate from batch k-BET test (kbet_accept_rate)
- Biological conservation
- HVG overlap between pre and post correction matrices
- Conservation of cell cycle scores between pre and post correction matrices
Batch Correction Parameters
Batch variable: sample_id
Batch correction applied: True
Batch correction method used: harmony
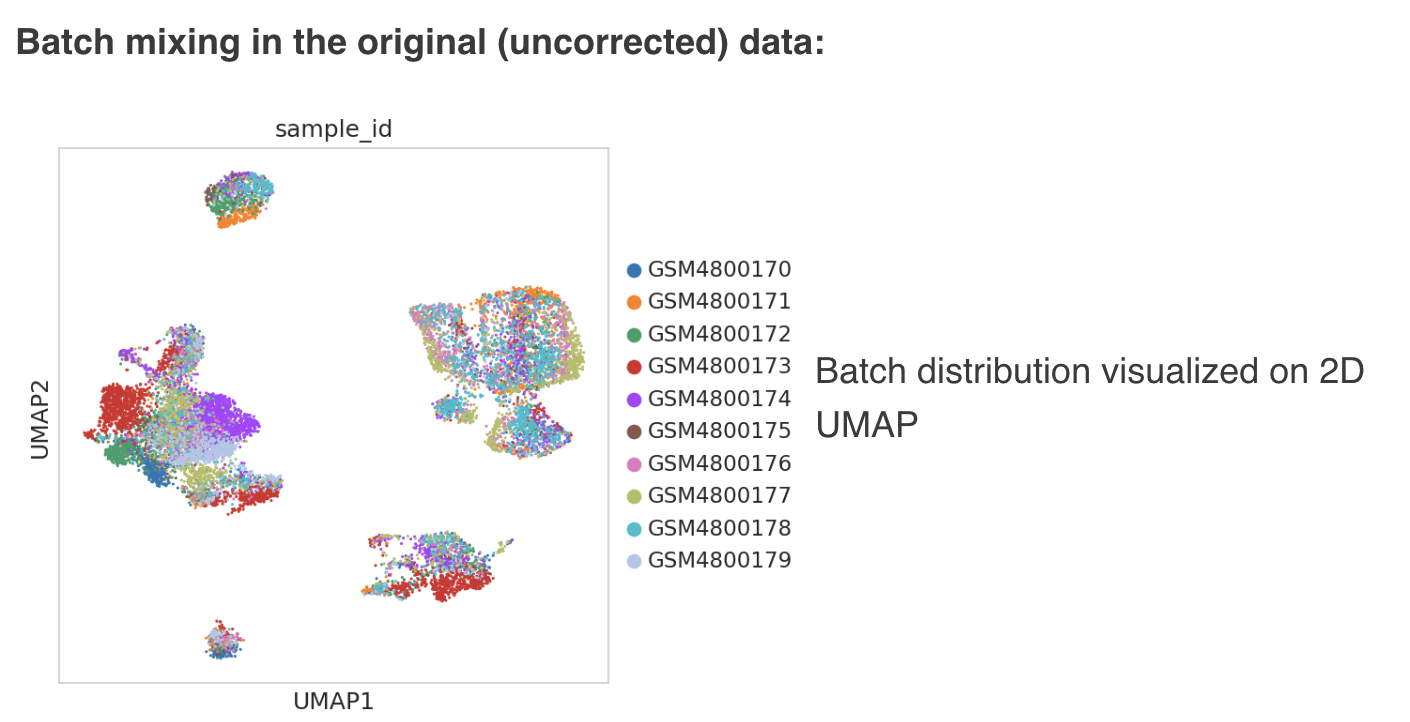
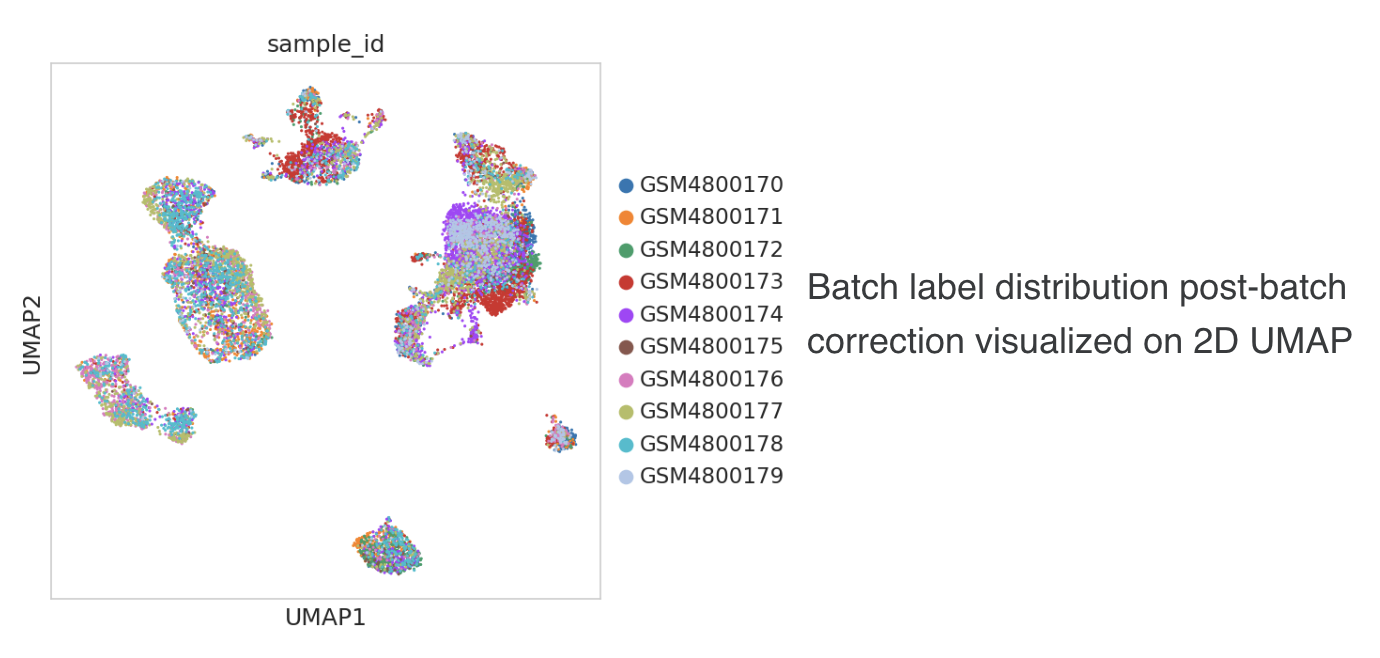
- Low-dimensional embeddings of the data
Parameters used for neighborhood graph construction following PCA:
- Number of PCs used for cell-cell distance computation
- Number of neighbors
-
For rendering UMAP and tSNE, default scanpy parameter settings were used.
-
Unsupervised cell clustering
Clustering parameters:
- resolution
-
number of clusters
-
Cell type annotation of clusters
-
Method used
- List of markers was used for cell type annotation (note that the trailing + or - indicates whether the corresponding marker genes are over-expressed (present) or under-expressed (absent) in cells of that type)
Eg.
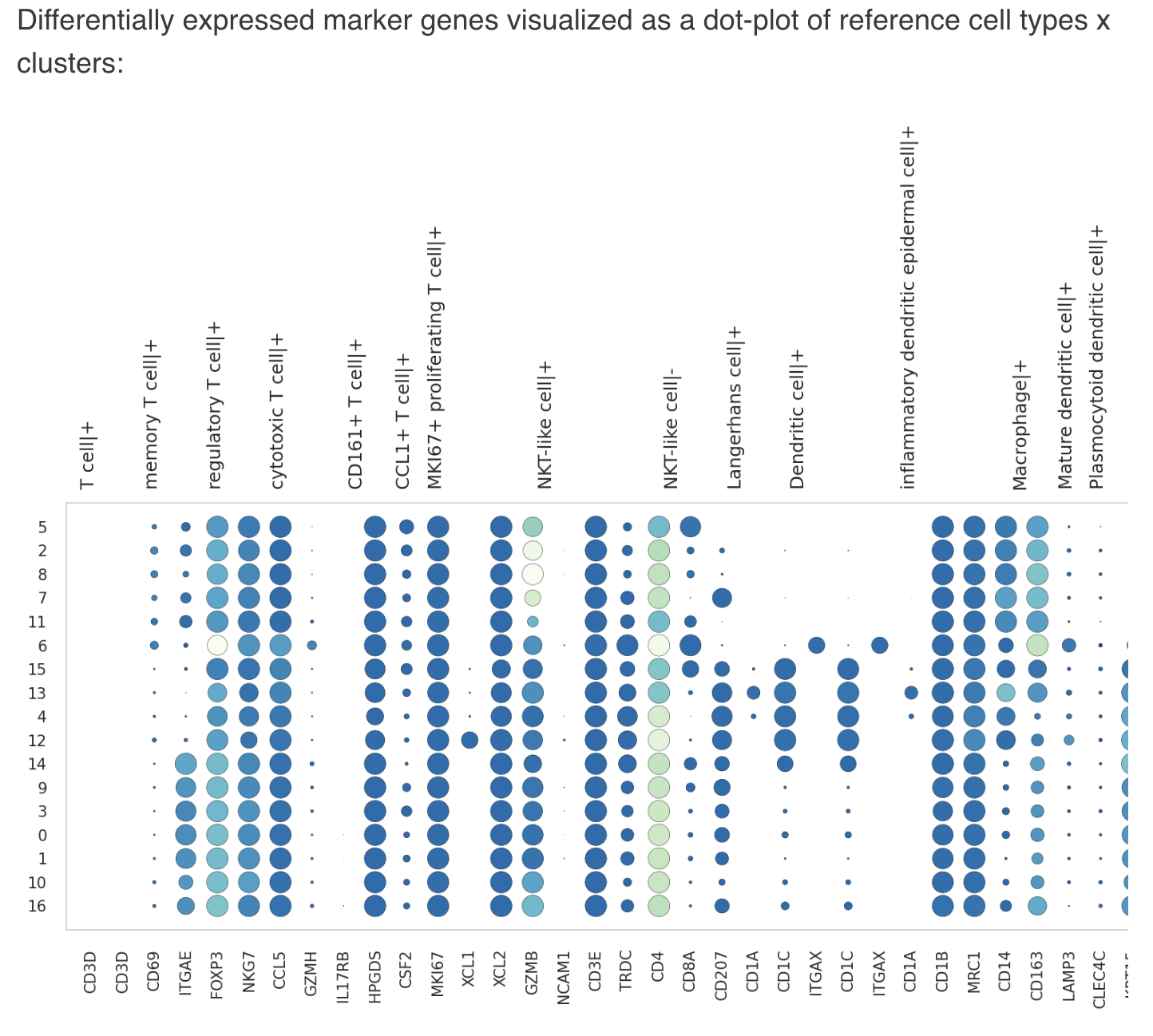
1 Basal keratinocyte|+ : KRT15, POSTN, COL17A1
2. CCL1+ T cell|+ : CSF2
3. CD161+ T cell|+ : IL17RB, HPGDS
4. Dendritic cell|+ : CD1C, ITGAX
5. Langerhans cell|+ : CD207, CD1A
6. Late differentiation keratinocyte|+ : KRT2
7. MKI67+ proliferating T cell|+ : MKI67
8. Macrophage|+ : CD14, CD163
9. Mast cell|+ : TPSAB1
10. Mature dendritic cell|+ : LAMP3
11. Melanocyte|+ : PMEL
-
Cell type predictions made using the author-provided cell types are given. Next to the predictions, the marker genes of the assigned cell type which are differentially expressed in the corresponding cluster are also highlighted (where found). Differentially expressed genes were identified by running the Scanpy rank_genes_groups function with the following parameter settings:
-
Statistical test: t-test
- Log2-fold change cutoff
- Adjusted p-value (BH)
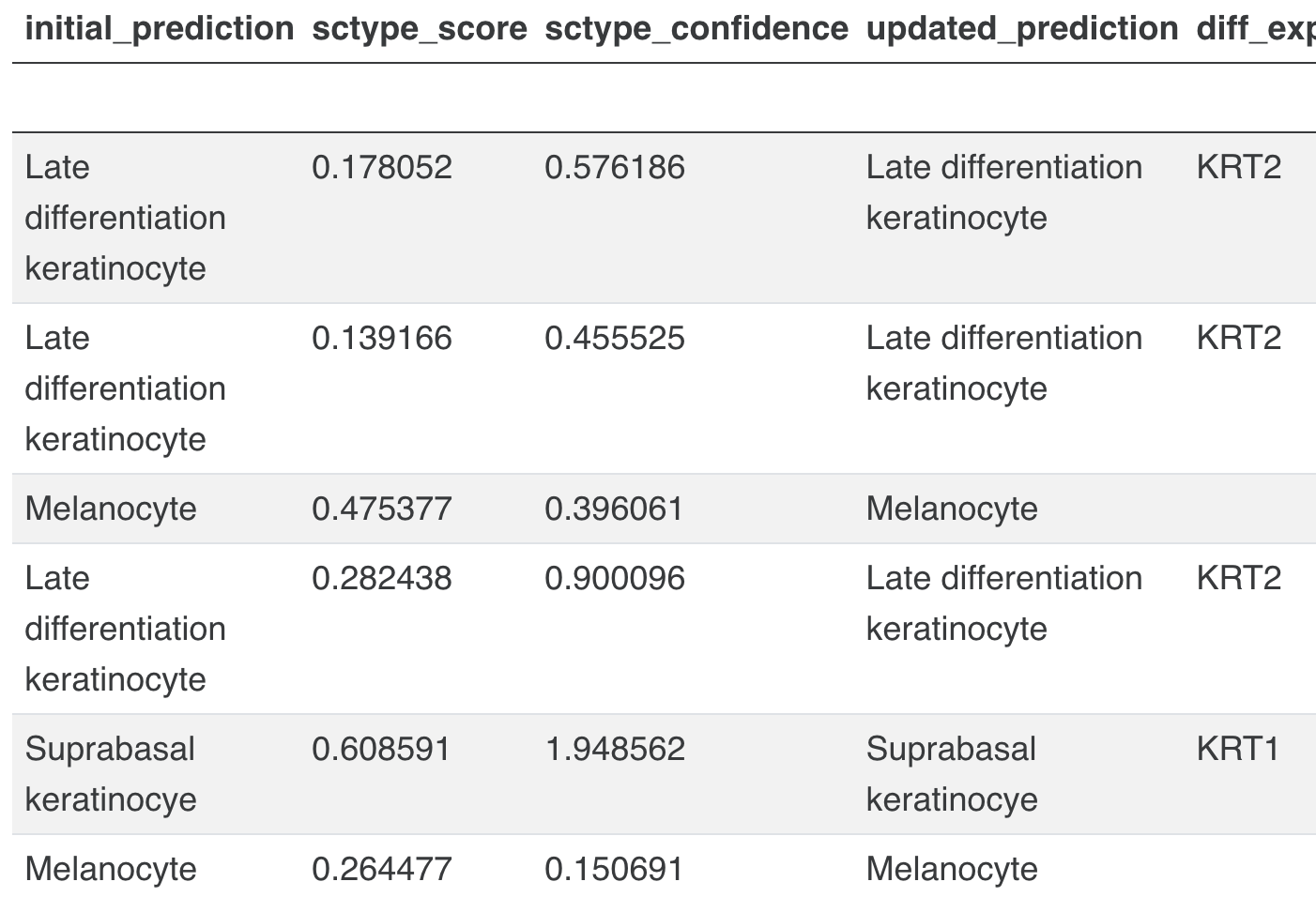
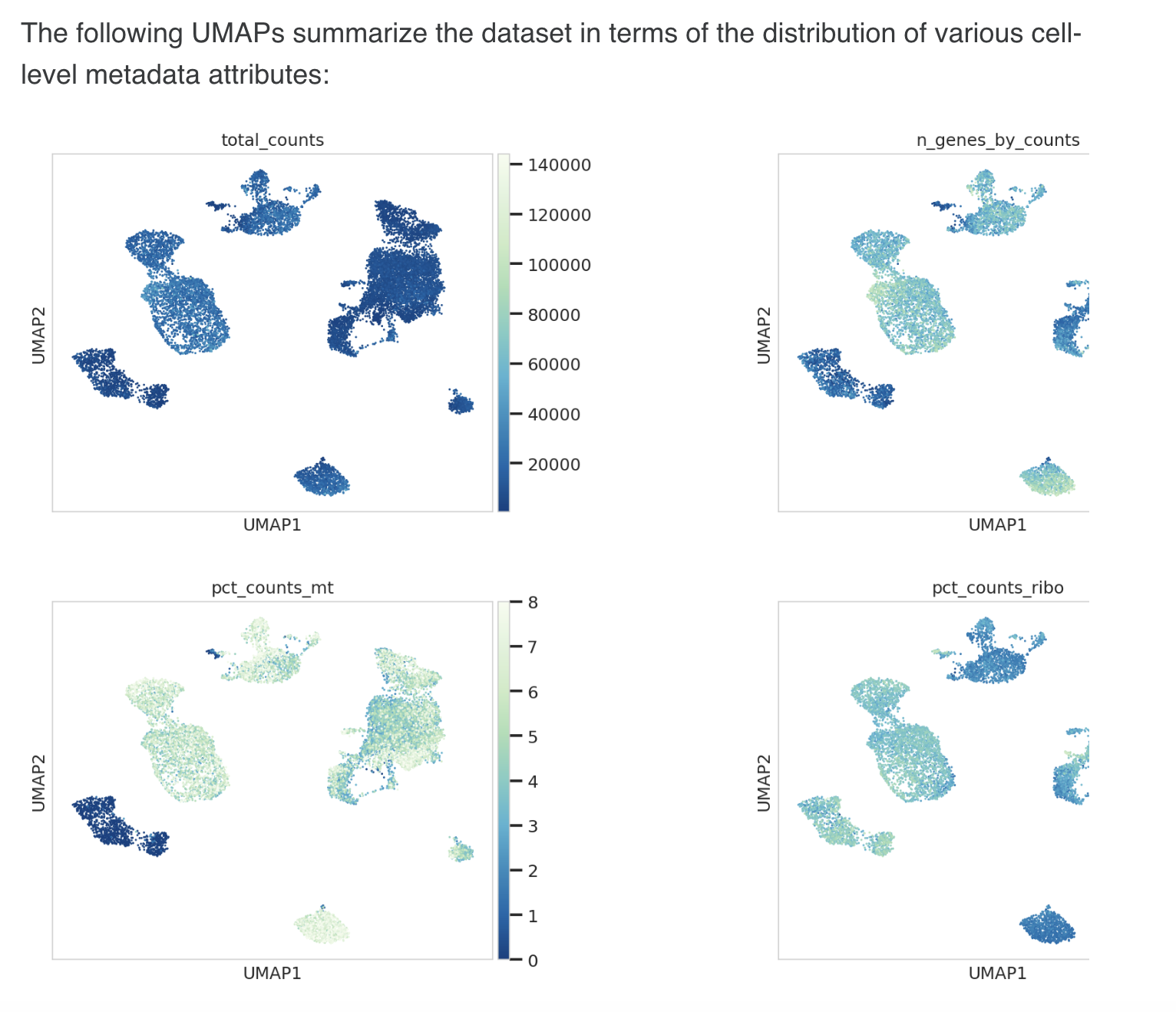
8.Cell-level metadata visualized on 2D UMAP
D) AnnData Object Summary
1. AnnData object with n_obs × n_vars = 13506 × 22199
2. obs: 'sample_id', 'cell_id', 'gpl', 'cid', 'title', 'organism', 'source_name', 'tissue', 'treatment', 'easi score (reduction)', 'chemistry', 'description', 'taxid', 'molecule', 'extract_protocol', 'type', 'status', 'submission_date', 'last_update_date', 'platform_id', 'channel_count', 'data_row_count', 'library_source', 'library_strategy', 'library_selection', 'instrument_model', 'data_processing', 'supplemental_files', 'curated_cohort_id', 'curated_cohort_name', 'curated_is_control', 'curated_organism', 'curated_sample_grade', 'curated_sample_stage', 'curated_sample_tnm_stage', 'curated_cell_line', 'author_cell_type', 'curated_disease', 'curated_drug', 'curated_strain', 'curated_tissue', 'sample_characteristics', 'curated_gene', 'age', 'curated_modified_gene', 'curated_genetic_mod_type', 'curated_disease_stage_value', 'curated_disease_stage_type', 'curated_cancer_stage_type', 'curated_cancer_stage_value', 'curated_treatment_name', 'curated_treatment_response', 'curated_max_age', 'curated_developmental_stage_value', 'curated_treatment_type', 'curated_donor_type', 'curated_sampling_site', 'curated_donor_sample_type', 'curated_gender', 'curated_age_unit', 'curated_developmental_stage_unit', 'curated_min_age', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_20.0_genes', 'total_counts_mt', 'log1p_total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'log1p_total_counts_ribo', 'pct_counts_ribo', 'total_counts_hb', 'log1p_total_counts_hb', 'pct_counts_hb', 'outlier', 'mt_outlier', 'doublet_score', 'predicted_doublet', 'clusters', 'polly_curated_cell_type', 'polly_curated_cell_ontology', 'curated_marker_present', 'curated_marker_absent', 'S_score', 'G2M_score', 'cell_cycle_phase'
3. var: 'mt', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'ensembl_id', 'feature_id', 'gene_id', 'ribo', 'hb', 'log1p_mean_counts', 'log1p_total_counts', 'highly_variable', 'highly_variable_rank', 'means', 'variances', 'variances_norm', 'highly_variable_nbatches', 'dispersions', 'dispersions_norm', 'highly_variable_intersection', 'G2M', 'S'
4. uns: 'batch_correction_details', 'batch_correction_metrics', 'bio_conservation_metrics', 'cell_cycle_phase_colors', 'cell_type_predictions', 'clusters_colors', 'curated_disease_colors', 'curated_tissue_colors', 'dendrogram_clusters', 'hvg', 'leiden', 'marker_gene_dict', 'neighbors', 'num_pc_dims', 'overall_integration_score', 'pca', 'polly_curated_cell_ontology_colors', 'polly_curated_cell_type_colors', 'processing_params', 'rank_genes_groups', 'sample_cell_numbers', 'sample_id_colors', 'sample_predicted_doublets', 'umap', 'unfiltered_cell_count'
5. obsm: 'X_pca', 'X_umap'
6. varm: 'PCs'
7. layers: 'counts'
8. obsp: 'connectivities', 'distances'

FAQs
Do all the single cell datasets on Polly have cell type annotation?
Availability of cell type annotation for datasets on Polly is as follows:
- Dataset with raw unfiltered counts - Not Available
- Dataset with Polly processed counts - Yes. Cell type annotation will be performed as requested by the user, the options are:
- Author’s cell type annotation as mentioned in the publication and mapped to cell type ontology
- Canonical cell types as available from CellMarkerDB and PangloDB for the given tissue and cell types from publication
- Cell annotations from users proprietary cell type to marker dictionary
Which are the different types of cell annotations available?
Currently, three types of cell-type annotations are available
- Raw unfiltered counts: Author cell type annotation mentioned in the publication are captured as metadata with no futher processing of data
- Polly processed cell type: Cell type annotation will be performed as requested by the user, the options are:
- Author’s cell type annotation as mentioned in the publication and mapped to cell type ontology
- Canonical cell types as available from CellMarkerDB and PangloDB for the given tissue and cell types from publication
- Cell annotations from users proprietary cell type to marker dictionary
Are source fields retained for a dataset?
All source fields are captured in the H5AD file which users can visualize through applications. However, fields available for searching through UI and Polly-python are restricted by schema due to performance constraints.
Are external data requests directly added to the Customer’s OmixAtlas?
Users can request for single-cell RNASeq datasets from the sources mentioned in the document above to be added to their atlas. Upon request, datasets will be made available in the customer’s Atlas directly.
Will QC reports be available for data audits/selection?
QC reports for a dataset will be generated on demand. Based on the customer requirements, datasets that pass the required QC criteria will be delivered.
The following QC metrics will be captured in the report: - Minimum total counts per cell - Maximum total counts per cell - Minimum number of genes per cell - Maximum number of genes per cell - Number of samples - Number of cells
Internal: We will generate QC reports for the datasets identified in the audit running them through the raw counts pipeline - These datasets will be populated in an Atlas and provided to the customer (without the option to download the H5AD file) - Customers can look at the details of the dataset (along with the QC report) and decide if they want to buy the dataset or not. - In case they want to buy, they send us a request along with their preference (raw counts or custom processed or author processed) either through Polly or via CSM - We then process the dataset as required by the customer and make it available in the customer Atlas (different from the data audit Atlas)
How will the availability of markers impact the delivery of datasets?
We will deliver datasets in such cases too. However, markers used for curation will be as follows: - We will use CellMarkerDB and PanglaoDB to identify canonical markers - If markers are not available in the databases above, it'll be custom curation - Availability of markers will checked and communicated within a day of the dataset request. Whether the curation required will be standard or custom, this information will also be communicated within a day of request
Is the subcluster information provided for a dataset?
- If subclusters are available as metadata, the subcluster information will be added to
author_cell-type - Each dataset will be split by the following parameters whenever applicable. So subcluster may exist as a separate dataset for the following:
- Disease
- Tissue
- Organism
- Assay
However the following will be the cases for custom subcluster annotation - If a dataset has splits as per patient or group of samples that don’t follow the above metadata split - If tissue is annotated with subclusters for eg. Heart Endothelial Cells are subtyped as artery, vein, etc. - Markers will be captured only from the main figure. These may have multiple tissues clustered together for a particular cell type. In cases, where authors have provided sub-cell types in additional figures, those markers are not captured which are specific to the additional UMAP/TSNEs. In order to capture these, it will be considered as a custom annotation. - If the publication’s marker database already has cell subtypes, then those markers will be used. If not, then it will be a custom annotation.
List of curated fields
Please find the link to the curated fields here