Introduction
Overview
The Labeled LC-MS/MS Workflow tool factors out the contribution from the natural abundance of each element from the signal of each isotopologue peak obtained from LC-MS techniques in a labeling experiment. It also allows you to visualize plots for NA corrected, fractional enrichment and pool totals for single as well as dual labeled data. The output of the natural abundance correction step is a table containing the raw abundances, fractional contributions and corrected isotopologues of the metabolites, calculated based on the library data provided.
Scope of the tool
- The tool supports data from LC-MS/MS and MRM/SRM experiments.
- Supports data from single as well as dual labeled experiments.
- Corrects data from 13C labeled experiments
- Plot fractional enrichment and pool total for a selected metabolite.
- It performs Phi calculations.
Getting Started
User Input
Labeled LC-MS/MS Workflow requrires three types of input files:
- El-MAVEN Output
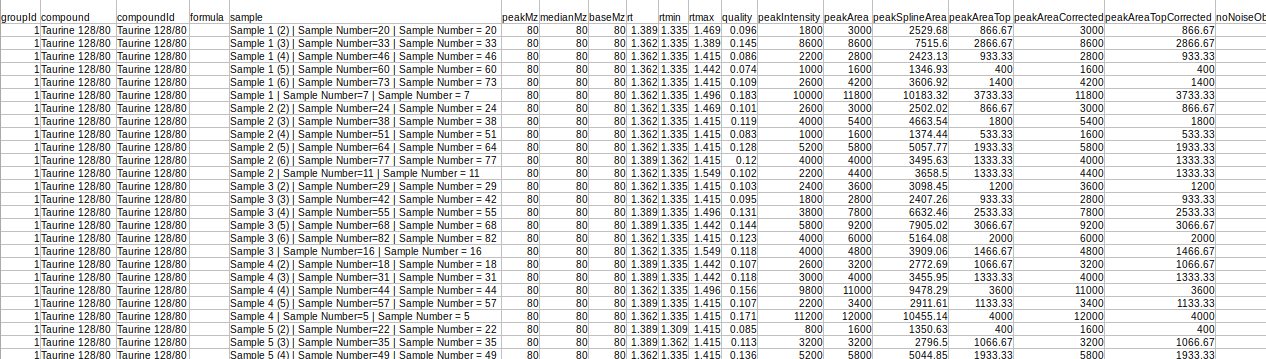
This file is the .csv output from El-MAVEN in peak detailed format.
Column Name | Description | Required/Optional | Validation Checks |
|---|---|---|---|
Original Filename | This column contains the name of the samples | Required | No format constraints |
Component Name | This column contains the fragment names | Required | Should be a non-negative number or NA |
Area | It contains the intensities values | Required | string of form parent mass/daughter mass |
Mass Info | It contains mass of parent fragment and daughter fragment “Parent Fragment Mass/Fragment Mass” | Required | string of form parent mass/daughter mass |
Sample Name | It contains cohort names. Required to identify cohort replicates. example A 0 min SCS, 10 min etc. | Required only if background correction is needed | No format constraints here |
- Fragment Mapping Metadata
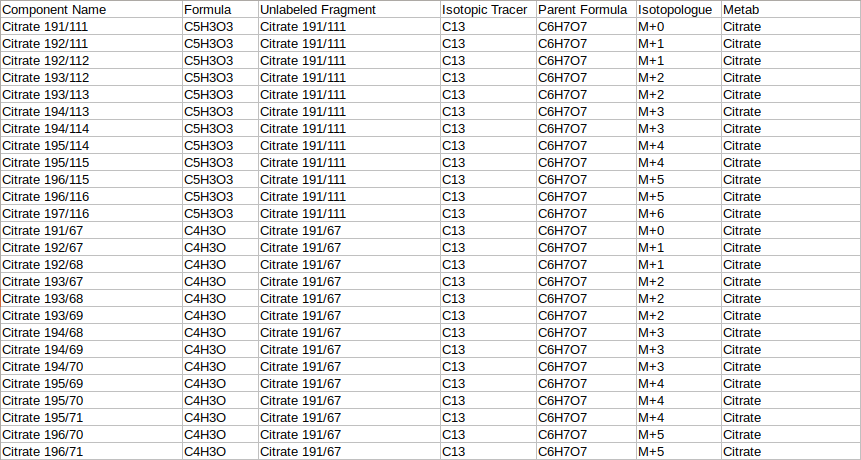
The fragment mapping metadata is a .csv, .xls, .xlsx or .txt file that contains mapping information for fragments, their metabolites, isotopic tracer, parent formula and daughter formula. This file's name should start with "metadata_mq".
Column Name | Description | Required/Optional | Validation Checks |
|---|---|---|---|
| Component Name | This column contains entries from "Component Name" column of the raw Multiquant file | Required* | No format constraints here |
| Unlabeled Fragment | The component name of the fragment which is completely unlabeled. example Citrate has two Unlabeled Fragments in the sample input data Citrate 191/111 (C5H3O3) and Citrate 191/67(C4H3O). Both are processed separately Example: metab, citrate, citrate 191/111 | Required* | No format constraints here |
| Formula | This column contains the chemical formula of the daughter fragment written in the format C4H3O | Required* | Validates formula by checking if elements in periodic table and atom numbers are integers |
| Parent Formula | This column contains the chemical formula of the parent fragment | Required* | Validates formula by checking if elements in periodic table and atom numbers are integers |
| Isotopic Tracer | This column contains the iso tracer. Example: if the iso tracer is carbon 13, it is written as C13 | Required* | Checks if the iso tracer is correctly |
- Background Mapping Metadata
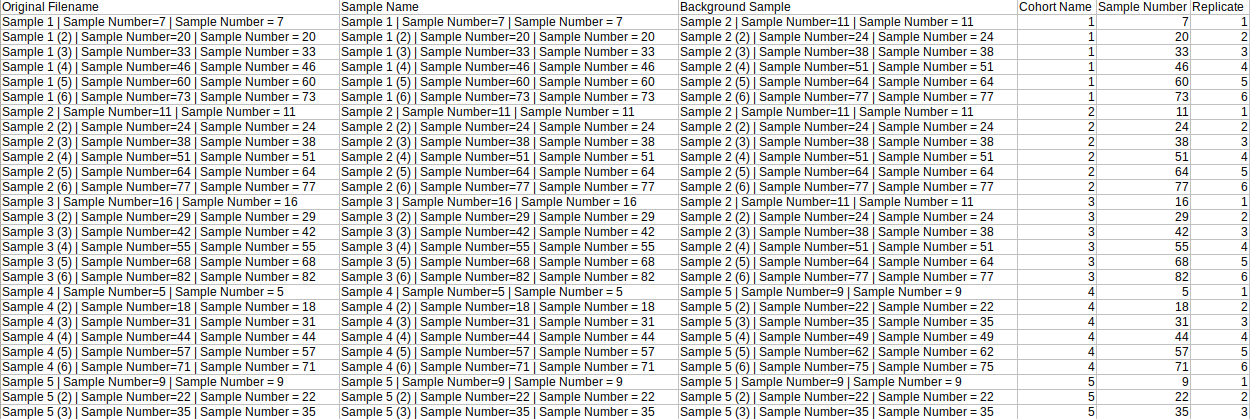
The background mapping metadata is a .csv, .xls, .xlsx or .txt file that contains sample metadata like names, background sample, cohort, etc. This file's name should start with "metadata_sample". As this file is used for background correction, it is optional.
Column Name | Description | Required/Optional | Validation Checks |
|---|---|---|---|
| Original Filename | This column contains the name of the samples. Each sample name occurs only once in this file and the names come from Original Filename column of raw multiquant file | Required* | Unique sample names, intersection with multiquant file not empty |
| Sample Name | This column contains cohort names. It is needed to identify the replicates of each cohort. | Required only if background correction needed | No format constraints here |
| Any number of additional columns | These columns contain metadata associated with sample names | Optional | |
| Background Sample | It contains the sample which is to be taken as reference for background correction | Required only if background correction is needed | The entries in this column are subsets of Original Filename |
Steps involved in data processing
- Prepare data files
- Upload data files
- Set analysis parameters and perform natural abundance correction
- Download corrected output files
- Visualize fractional enrichment and pool total plots
- Perform Phi calculation by uploading NA corrected file
Caveats
- The intensity file should be the El-MAVEN output in peak detailed format.
- The fragment mapping metadata file's name should start with "metadata_mq".
- The background mapping metadata file's name should start with "metadata_sample".
Tutorial
Select Labeled LC-MS/MS Workflow from the dashboard under the Metabolomics Data Tab as shown in Figure 5. Create a New Workspace or choose from the existing ones from the drop-down and provide the Name of the Session to be redirected to Labeled LC-MS/MS Workflow's upload page.
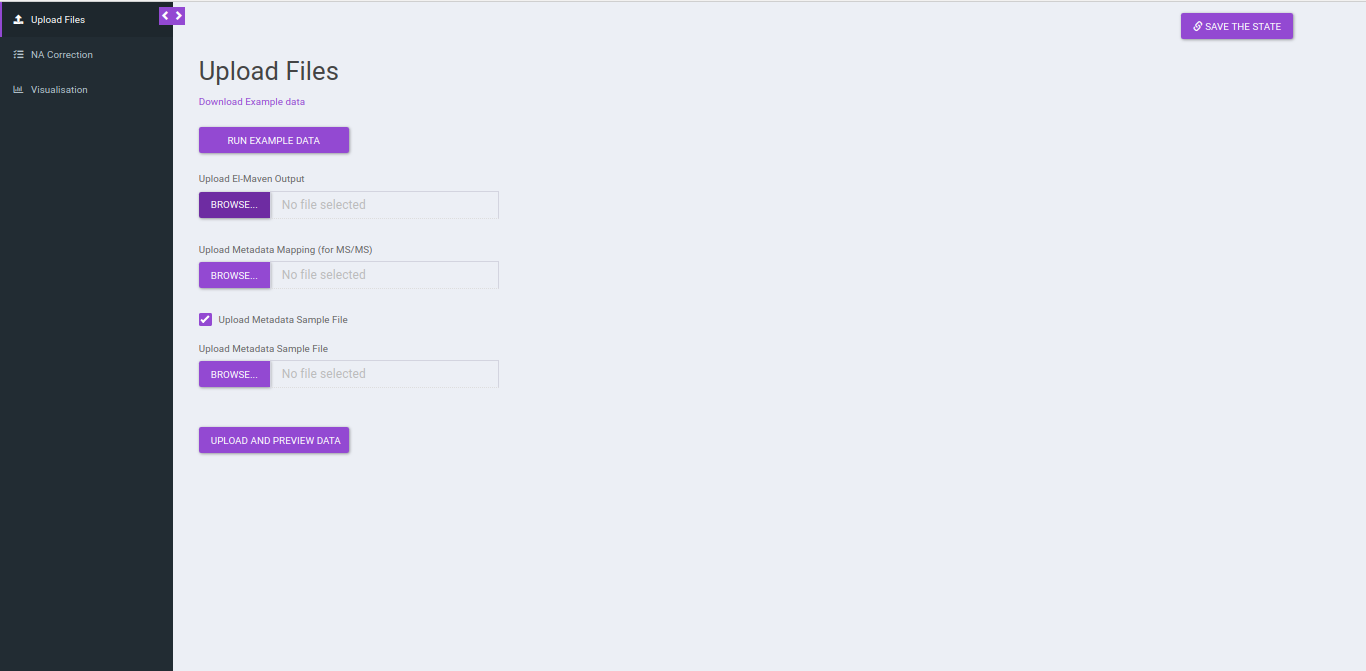
Upload Files
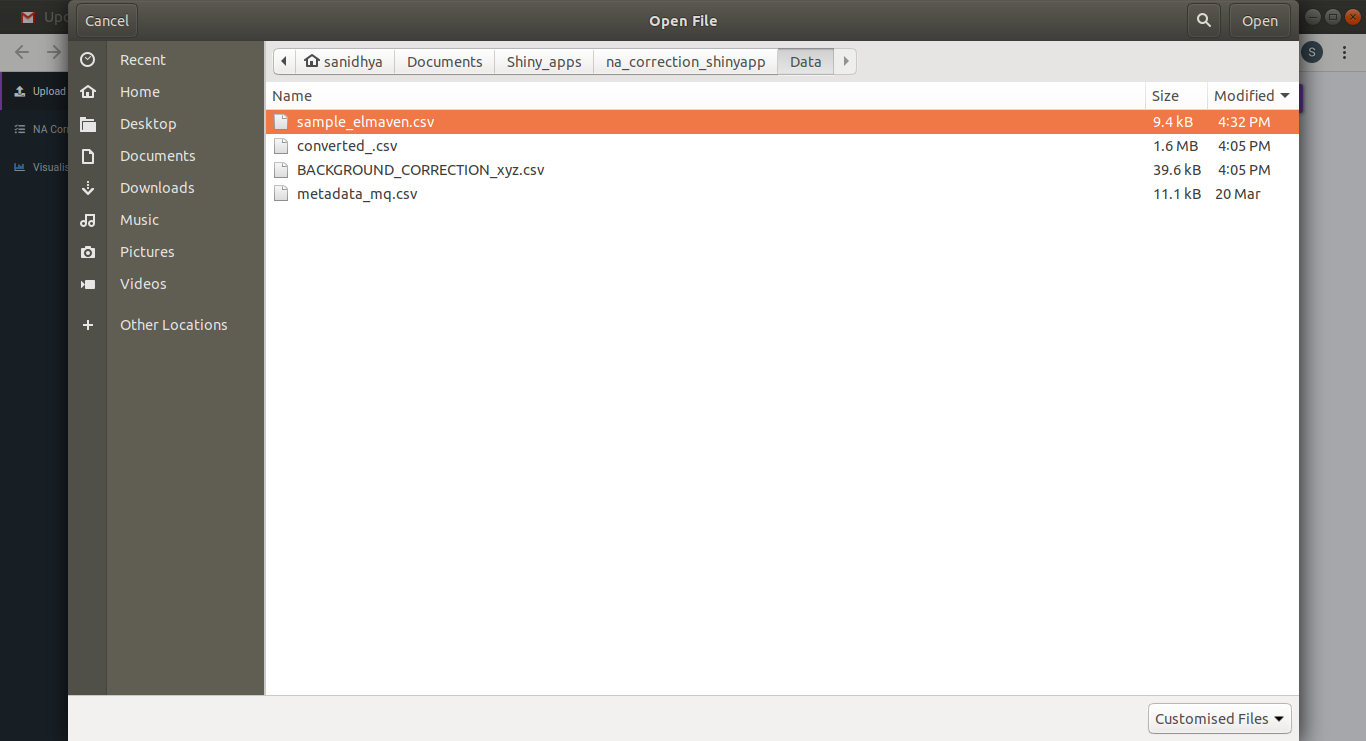
Click on Upload El-MAVEN Output and Upload Cohort FIle to upload the intensity and metadata files respectively. This is optional. The metadata is not used in the NA correction, however, if you wants to visualize plots, the sample-cohort mapping would be required. Click on Run to proceed.
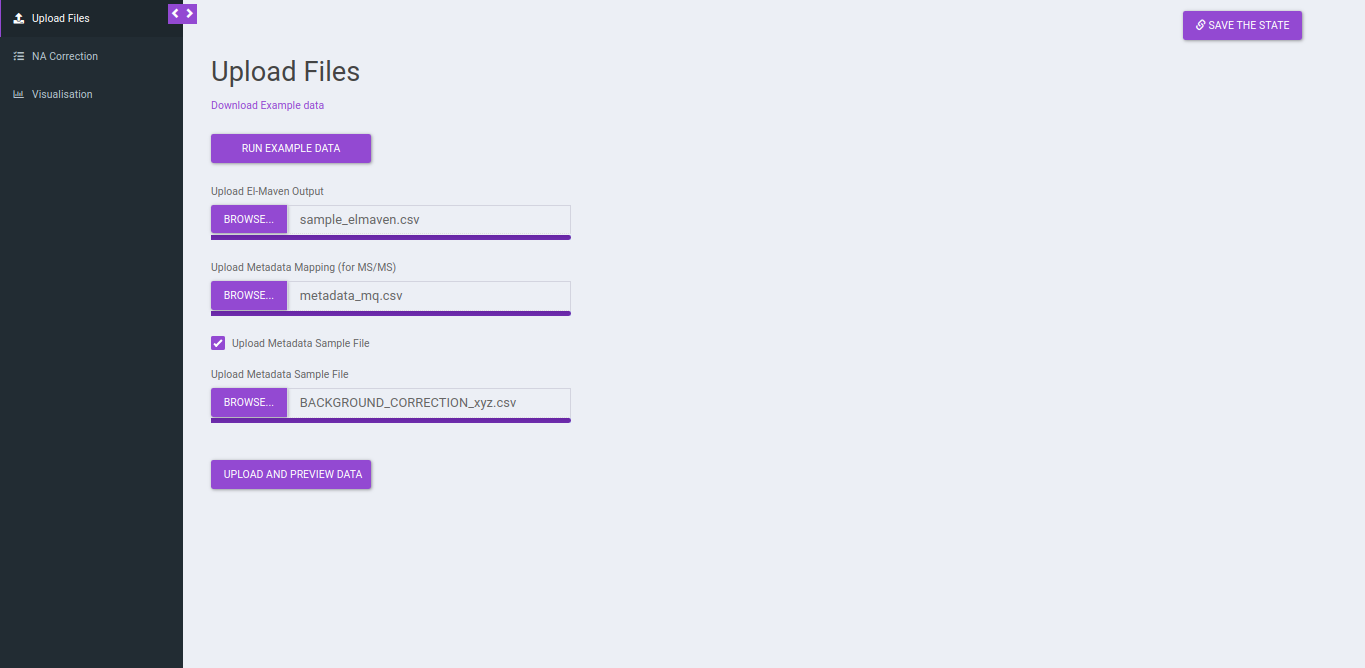
If you do not upload a metadata file and upload a metadata sample file you will be provided with the option to Drop Samples as well as Map Replicate to Background Samples.
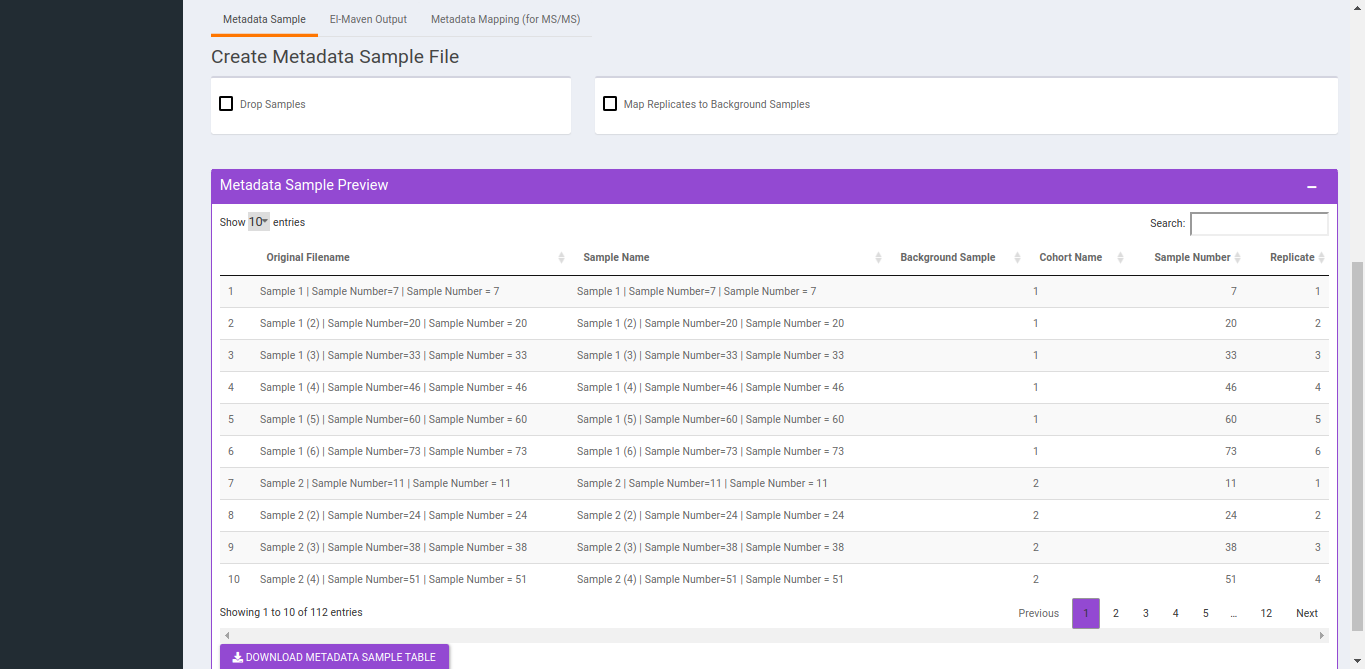
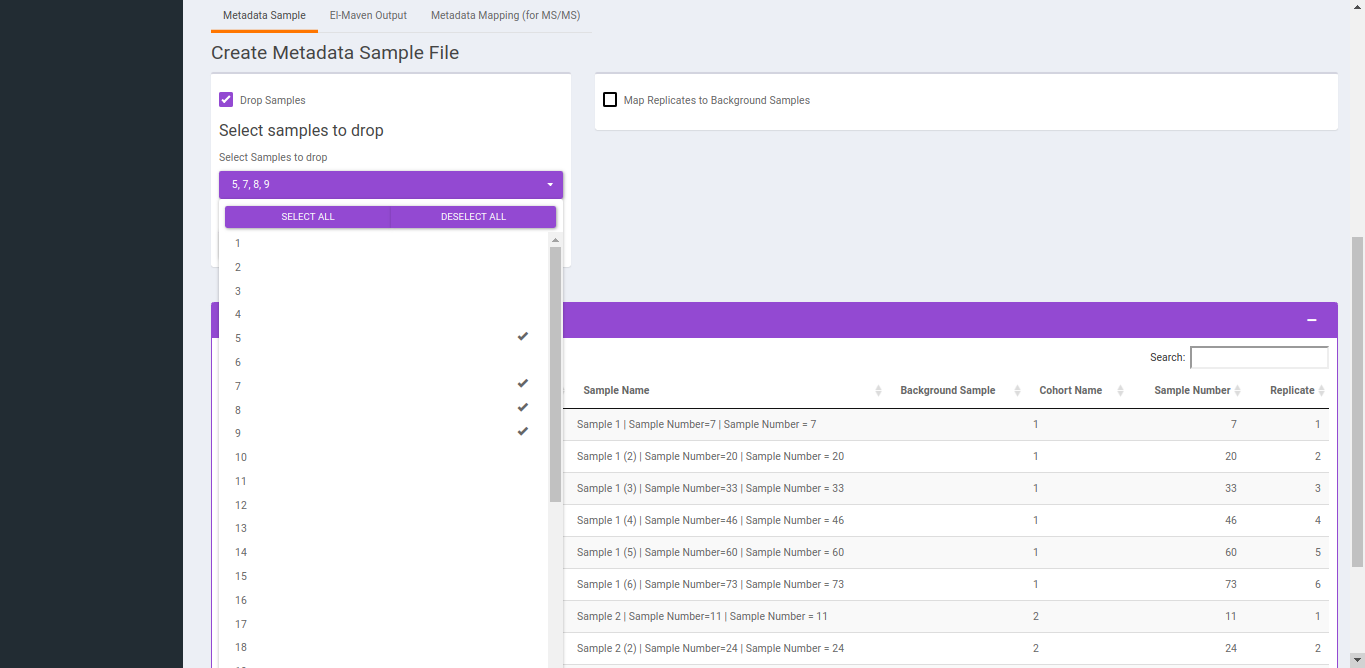
- To Drop Samples check the drop samples checkbox and select sample(s) to drop and hit Drop Samples.
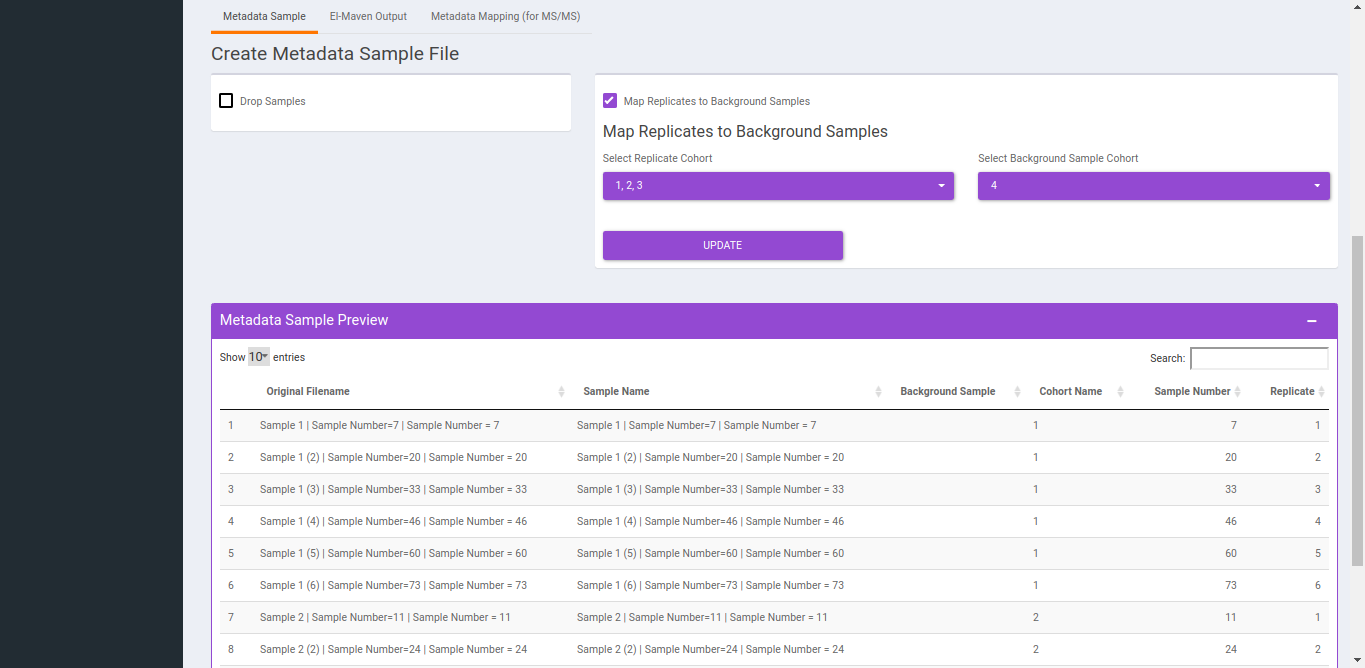
- To replicate samples to background samples, select the Replicate Cohort and Background Sample Cohort and hit Update metadata.
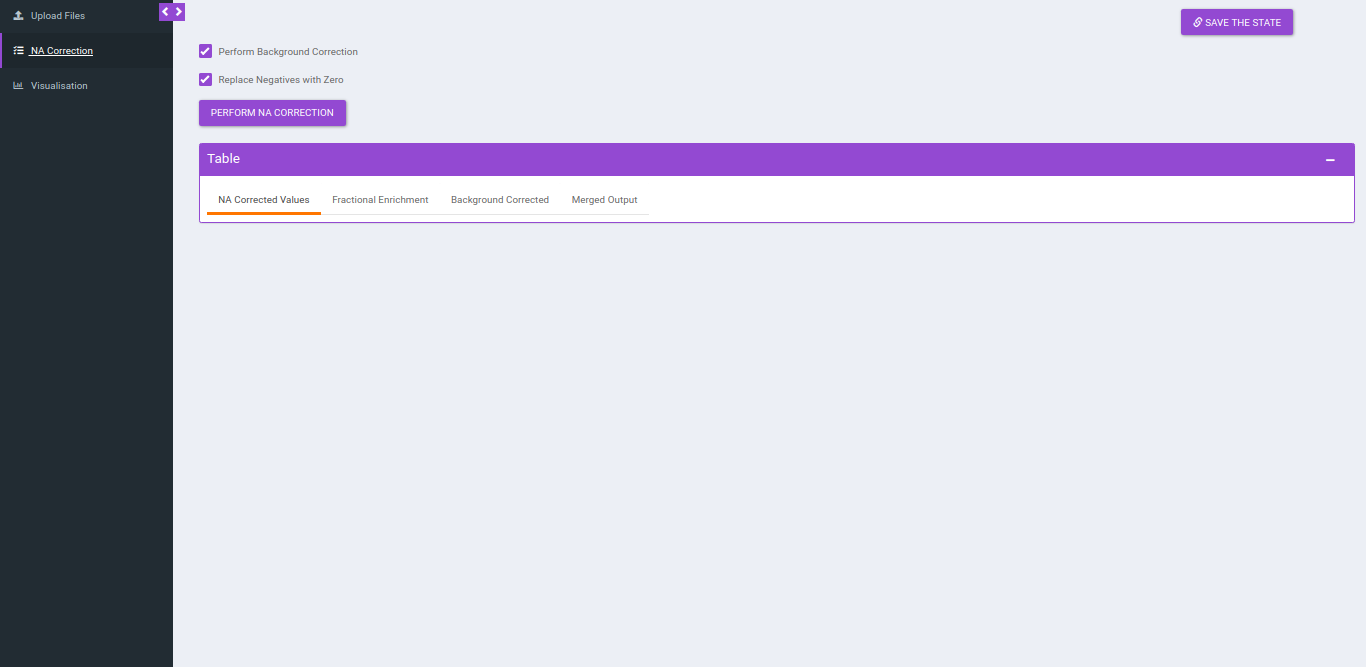
NA Correction
You can navigate to NA correction tab by either clicking on Go to NA Correction option or by selecting the NA Correction tab. There are two options to perform NA correction:
- Check Perform Background Correction checkbox to perform background correction.
- Replace negatives with zero is selected by ddefault. This option replaces any negative intensities obtained with 0.
Note:
- The sum of natural abundances of all the isotopes of an element should be 1.
After selecting the parameters, click on Perform NA Correction, to get the NA corrected intensities.
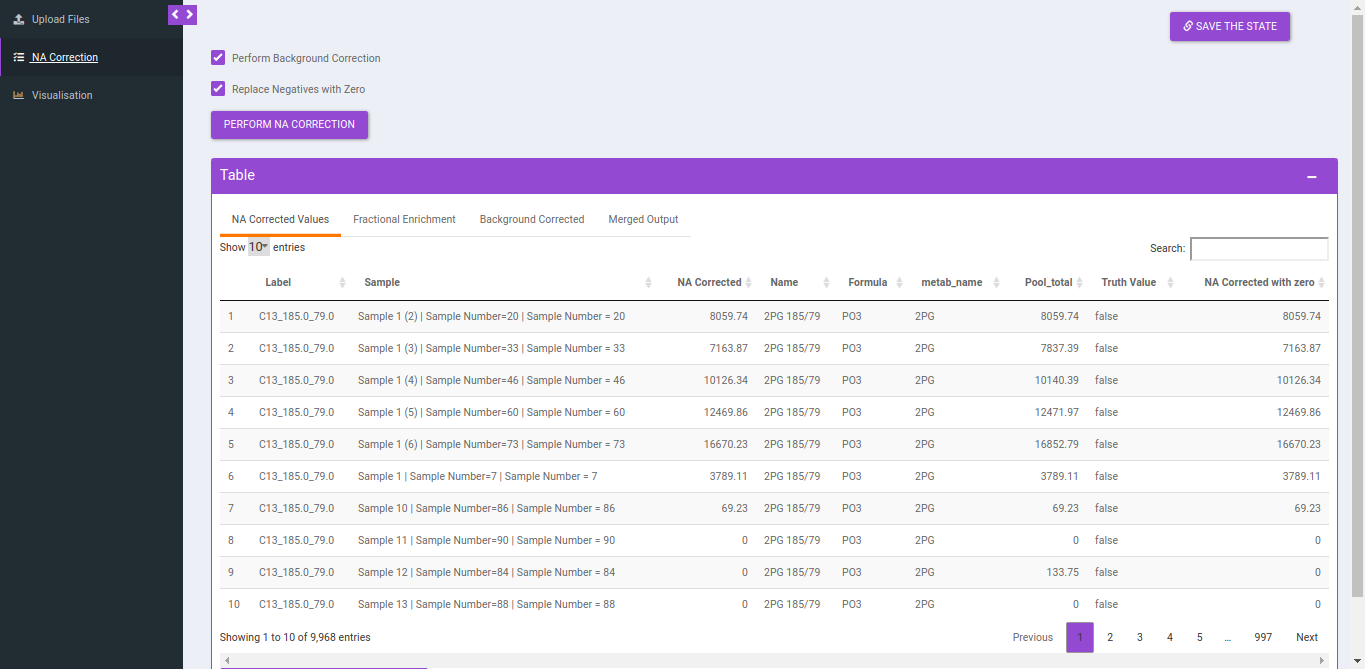
Output
NA Correction data file
Column Name | Description | Required/Optional | Validation Checks |
|---|---|---|---|
| Name | Name of the unlabelled fragment | metadata_mq | Unlabelled fragment |
| Label | It gives label information by the entries of type isotracer_parentmass_daughtermass
| Entries come from Isotracer column of metadata_mq masses from Mass Info of raw multiquant | |
| Formula | Contains chemical formula of the daughter fragment | metadata_mq | |
| Sample | Contains sample name | Raw intensity file | Original filename |
| NA corrected | NA corrected intensities | ||
| NA Corrected with 0 | Negative values are replaced with zero |
Background Correction data file
Column Name | Description | Required/Optional | Validation Checks |
|---|---|---|---|
| Name | Name of the unlabelled fragment | metadata_mq | Unlabelled fragment |
| Formula | Contains chemical formula of the daughter fragment | metadata_mq | |
Label | It gives label information by the entries of type isotracer_parentmass_daughtermass
| Entries come from Isotracer column of metadata_mq masses from Mass Info of raw multiquant | Original filename |
| Sample | Contains sample name | Raw intensity file | |
| Background corrected | NA corrected intensities | ||
| Background Corrected with 0 | Negative values are replaced with zero |
Fractional enrichment data file
Column Name | Description | Required/Optional | Validation Checks |
|---|---|---|---|
| Name | Name of the unlabelled fragment | metadata_mq | Unlabelled fragment |
| Formula | Contains chemical formula of the daughter fragment | metadata_mq | |
| Label | It gives label information by the entries of type isotracer_parentmass_daughtermass
| Entries come from Isotracer column of metadata_mq masses from Mass Info of raw multiquant | |
| Sample | Contains sample name | Raw intensity file | Original file name |
| Fractional enrichment | NA corrected intensities |
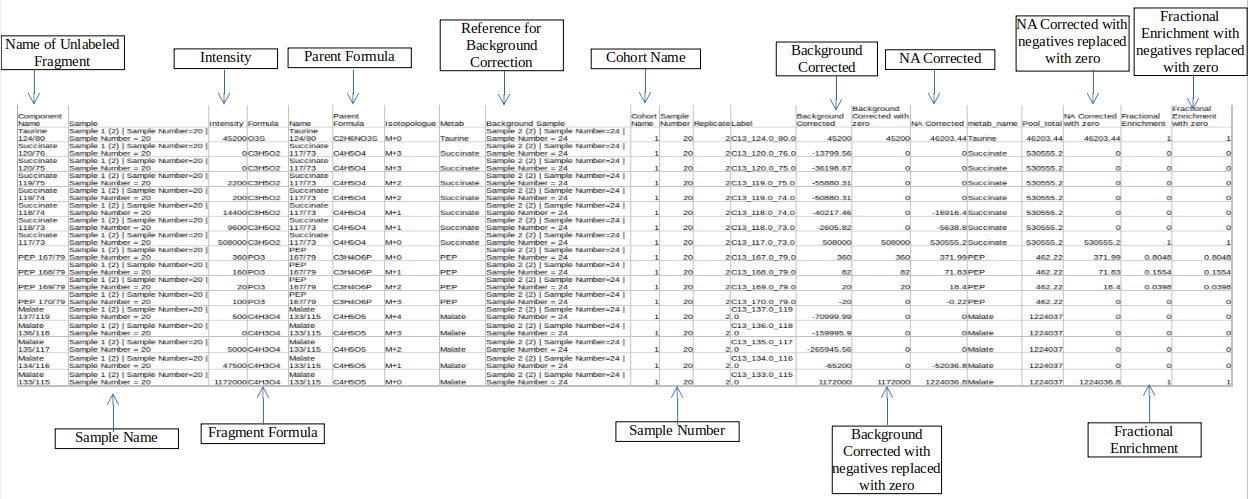
Merged Output
Column Name | Description | Required/Optional | Validation Checks |
|---|---|---|---|
| Sample | Contains sample name | Raw intensity file | Original file name |
| Parent Formula | Contains formula of the parent fragment | metadata_mq | Parent Formula |
| Name | Name of the unlabelled fragment | metadata_mq | Unlabelled fragment |
| NA Corrected | NA corrected intensities | Entries come from Isotracer column of metadata_mq | |
| Label | 14">It gives label information by the entries of type isotracer_parentmass_daughtermassc3">: C13_123_23 | Entries come from Isotracer column of metadata_mqmasses from Mass Info of raw multiquant | |
| Intensities | Contains raw intensities | Raw intensity file | Area |
| Formula | Contains chemical formula of the daughter fragment | metadata_mq | |
| Enrichment | Fractional enrichment values | ||
| Component name | Contains the name of the fragments | Raw intensity file | Component name |
| Background corrected | Background corrected intensities | ||
| Pool total | pool total of a metabolite in a sample |
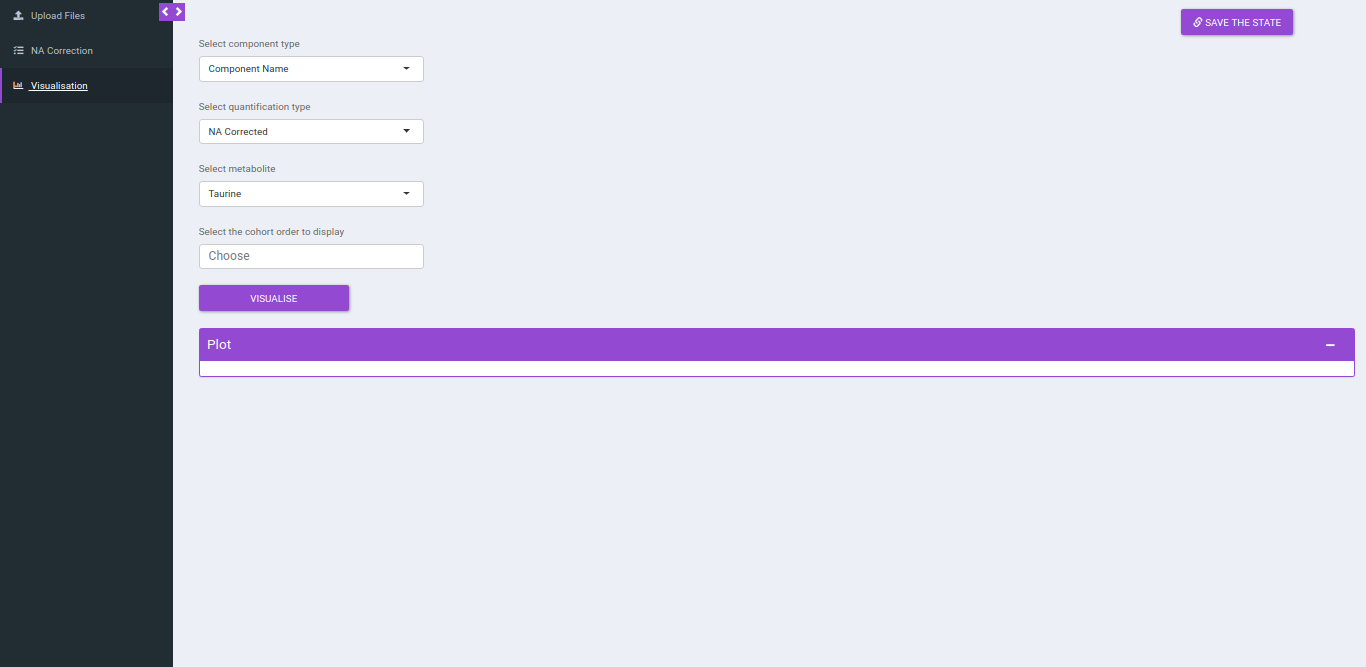
Visualization
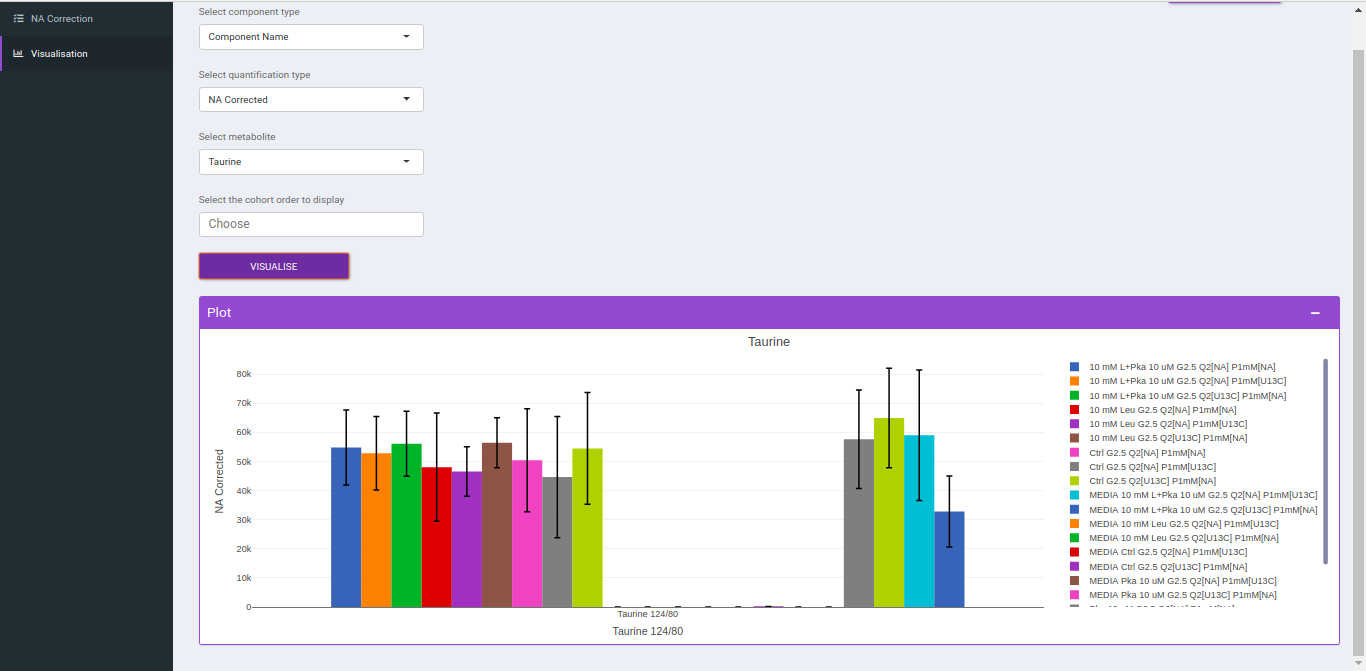
After NA correction, you can visualize the NA corrected intensities, fractional enrichment and pool total plots that are generated according to the metabolite and quantification type.
- Select component type: This allows you to select the component types: Component name, Isotopologue or Pool total for the plot.
- Select a metabolite: This allows you to select a metabolite from the drop down options of all metabolites detected as per the intensity file uploaded.
- Select quantification type: This allows you to select a quantification type from the drop down options of Intensity, NA corrected, NA corrected with zero, Fractional Enrichment and Fractional Enrichment with zero. The default value, in this case, is NA corrected.
- Select the cohort order to display: Here you can select which cohort(s) to display. The tab by default shows all the cohorts.
Click "Run* to plot the fractional enrichment plot with all the labels present and for separate label elements and the pool totals plot.
PhiBETA Tab
This tab enables you to perform Phi analysis. The term 'Phi' denoted by 'φ' is ratio of fractional enrichments of isotopomers/isotopologues of a product to the fractional enrichments of isotopomers/isotopologues of a precursor in the pathway.
-
Consider,
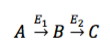 , then
, then 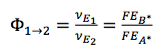 , which means if there is another flux contributing to the generation of B, then other pathway contributes to FEB* , in this case, 𝛷AB < 1
, which means if there is another flux contributing to the generation of B, then other pathway contributes to FEB* , in this case, 𝛷AB < 1 -
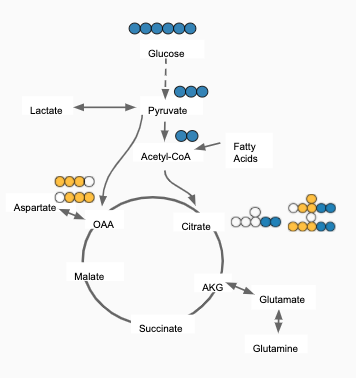
For eg: In the image shown below, Acetyl-CoA is generated from Pyruvate and with some contribution from Fatty acids. Then, 𝜱PAc < 1 as Acetyl-CoA is also formed from Fatty Acids. If the only contributor is Pyruvate then 𝜱PAc = 1
Calculate Phi: This allows you to set the parameters to calculate the Phi values based on the formula specified above. You can upload NA corrected file if it has been performed externally. In case, NA correction is performed within the app, there is no need to upload the NA corrected file and you can directly perform Phi calculation.
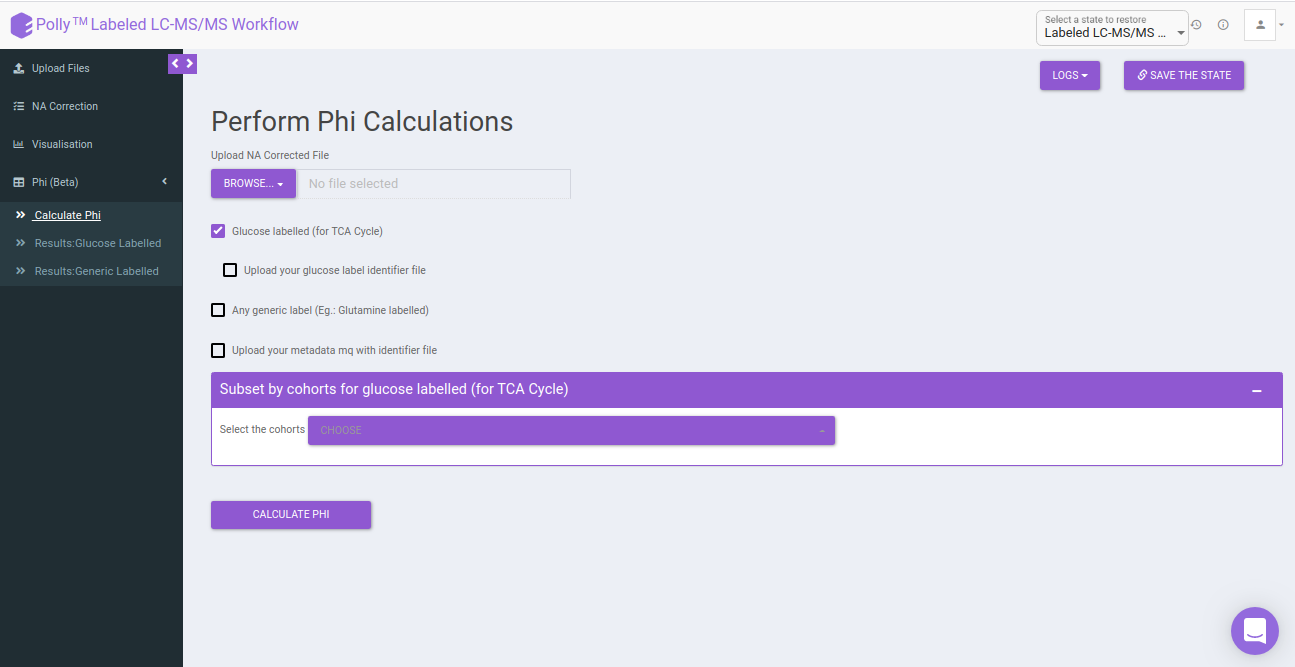
Select the following options for Phi calculation:
-
Glucose labeled (for TCA cycle): In case the data is 13C Glucose labeled, you can select this option for calculating the Phi. This will point to the metabolites of the TCA cycle contributing to the generation of that metabolite.
-
Upload your Glucose label identifier file: By default, identifiers file with the expressions present within the app is used. If you want to make use of the identifier file for Glucose with additional expressions, you can upload the Phi expression file. Here, you will be provided with the option to upload Phi Expression File and Intermediate Expression File.
-
Any generic label (eg: Glutamine Labeled): In case you have any other generic label data other than Glucose, you can make use of this option. The app will perform Phi calculation in the same way as for 13C Glucose labeled elements.
-
Upload your generic label identifier file: The app by default has the identifier expressions file for glutamine label. If at all, you have the identifier file for glutamine with additional expressions or any other generic label, you can select onto this option and further upload the identifier expression file for the same.

- Upload your metadata mq with identifier file: The app by default has the metadata mq identifier loaded, but in case you have made use of any additional expressions for the above parameters, you will have to upload your own metadata mq identifier file. Keeping it unchecked would utilize the metadata mq file within the app.
-
Subset by cohorts for glucose labeled (for TCA Cycle): You can subset the specific cohorts that belong to the Glucose labeled (for TCA Cycle) to proceed with the Phi calculation. You can type out a characteristic string that denotes the particular cohort and select onto the required cohorts from the dropdown.
-
Subset by cohorts for generic labeled: You can subset the specific cohorts that belong to the belong to generic labeled to proceed with the Phi calculation. You can type out a characteristic string that denotes the particular cohort and select onto the required cohorts from the dropdown.
After uploading the necessary files, click on Calculate Phi.
Results: Glucose Labeled: This tab contains the output to Phi calculation performed on 13C Glucose samples. It consists of the following sub-tabs namely:
- Calculated Phis: This sub-tab contains a table of Phi values belonging to each identifier across the different samples. You can download the data as a CSV file as well.
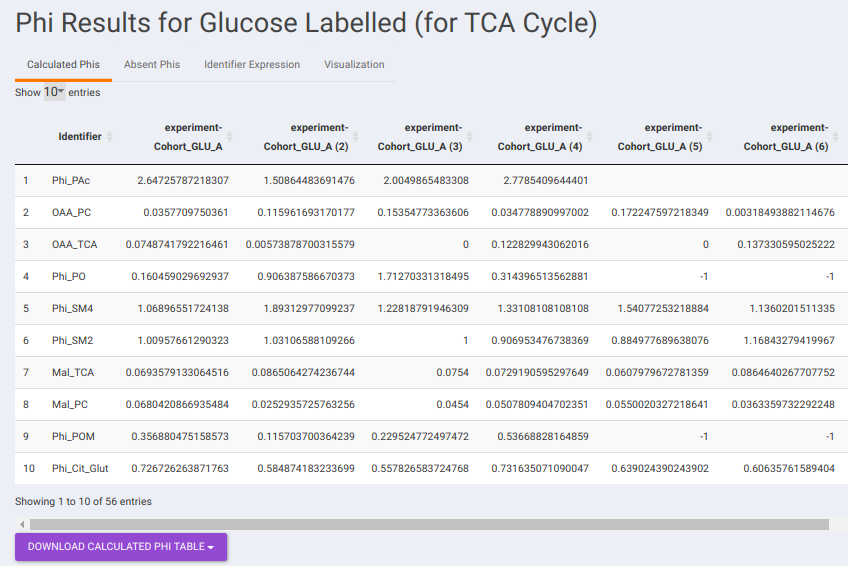
-
Absent Phis: This sub-tab contains a downloadable list of absent Phi values that could not be calculated possibly because of missing fragments withing the data provided.
-
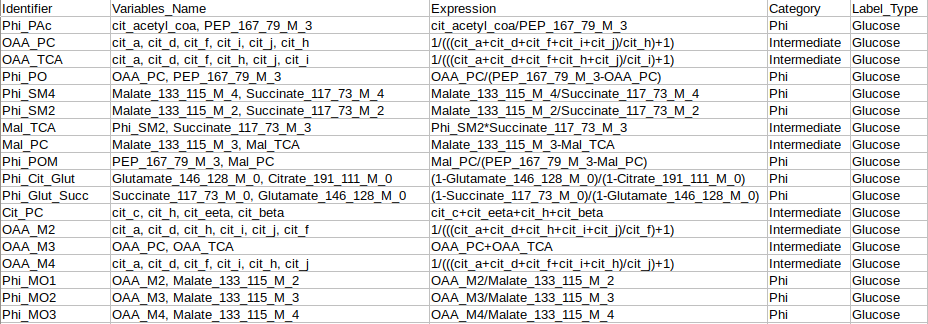
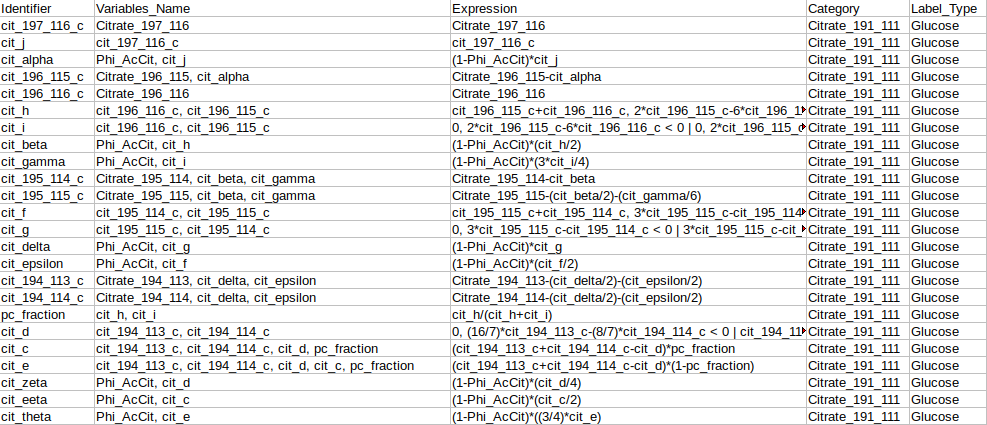
Identifier Expression: This sub-tab displays the list of identifier formulas used to calculate Phi values for the Glucose labeled data.

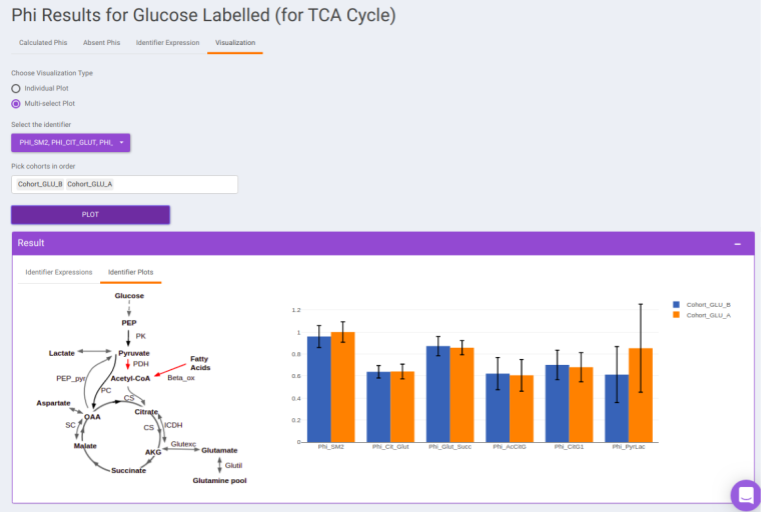
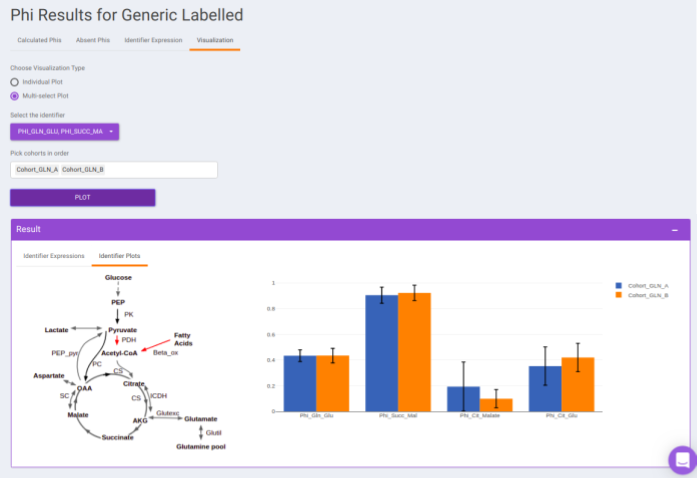
- Visualization: The Visualization sub-tab consists of the type of visualizations to view the Phi of identifiers across the cohorts. Select Individual Plot or Multi-select Plot and enter cohorts to view in the visualization space. Further, you can select the identifiers of interest from the dropdown provided under Select the identifier option. You can as well specify the cohorts order.
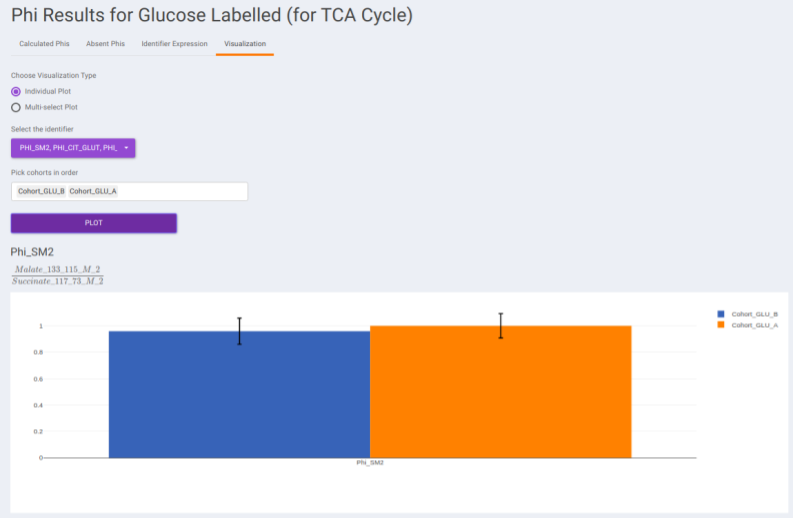
Results: Generic Labeled: In case, you have selected generic labels i.e., other than 13C Glucose, this tab contains the output to Phi calculation performed on the other samples. It consists of the following sub-tabs namely:
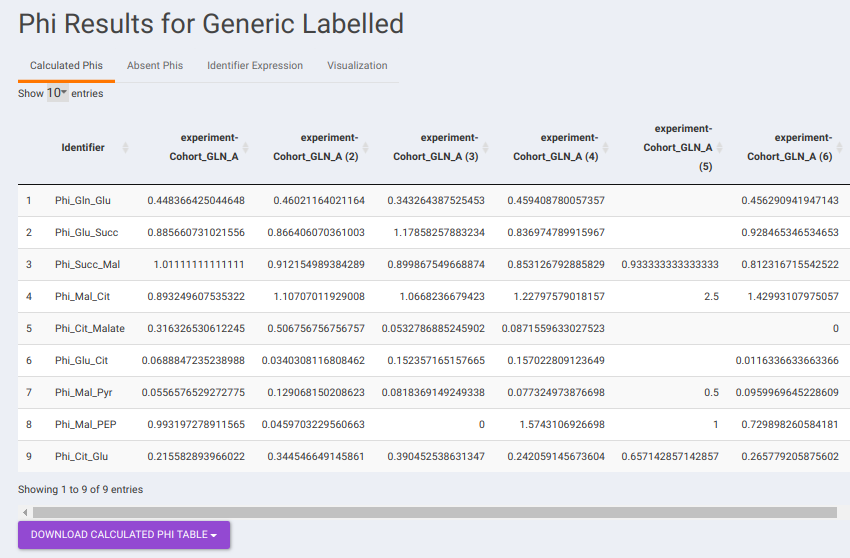
- Calculated Phis: This sub-tab contains a downloadable list of Phi values that have been calculated for each identifier.
-
Absent Phis: This sub-tab contains a downloadable list of absent Phi values that the app could not match with the identifier table.
-
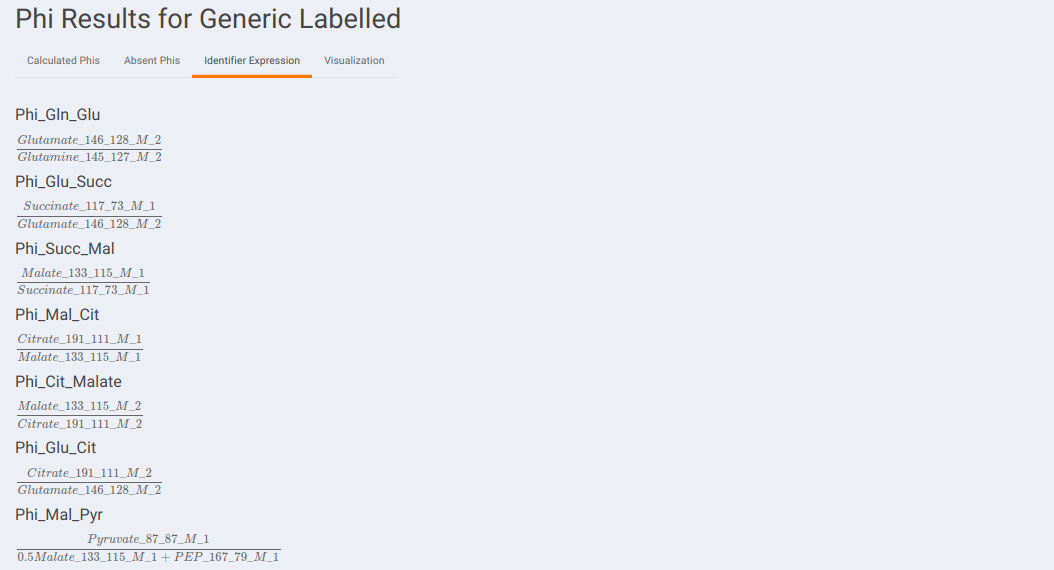
Identifier Expression: This sub-tab displays the list of identifier formulas used to calculate Phi values for the generic labeled data.
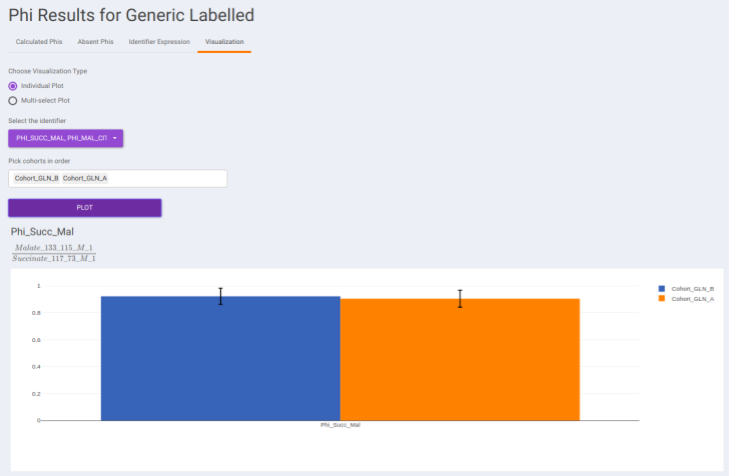
- Visualization: The Visualization sub-tab consists of the type of visualizations to view the Phi of identifiers across the cohorts. Select Individual Plot or Multi-select Plot and enter cohorts to view in the visualization space. Further, you can select the identifiers of interest from the dropdown provided under Select the identifier option. You can as well specify the cohorts order.
Details about the app
Autodetection of indistinguishable isotope
A new feature in Corna has the ability to auto-detect indistinguishable isotopes in experiments with dual tracers. Some high-resolution mass spectrometer instruments are able to distinguish isotopes like 13C from 15N. The packages available for performing natural abundance correction on these data assume infinite resolution, which means that it is assumed that if 13C can be resolved from 15N at all masses and it can also be resolved from other isotopes like 2D. However, this assumption becomes invalid as the resolution of the machine varies with the mass of the metabolite. Corna does not assume ultra-high resolution and corrects for partial indistinguishability in the data.
Fractional enrichment
Fractional enrichment is calculated for each label corresponding to every metabolite in a sample.
Fractional enrichment = corrected intensity of a label / sum of corrected intensities for all isotopologues including PARENT
Pool total
Sum total of intensities of every isotopologue (label) for each metabolite in a sample.
Pool total of metabolite ‘m’ in sample 1 = Sum (intensities of all labels of ‘m’ in sample 1)
References
-
Lide, D. R., “CRC Handbook of Chemistry and Physics (83rd ed.). Boca Raton”, FL: CRC Press. ISBN 0-8493-0483-0, 2002.
-
Moseley H., “Correcting for the effects of natural abundance in stable isotope resolved metabolomics experiments involving ultra-high resolution mass spectrometry”,BMC Bioinformatics, 2010, 11:139.